字符集
字符集是由一对方括号“[]”括起来的字符集合。表示匹配[]包含的多个中的其中一个。
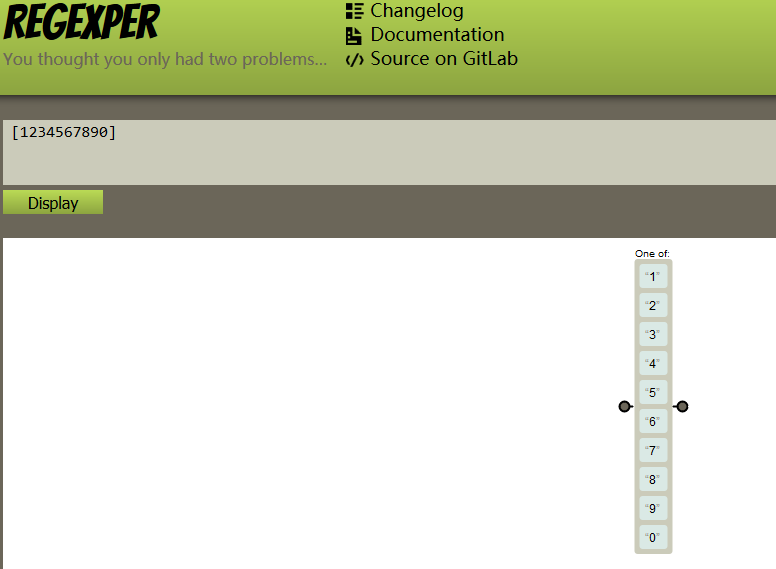
[1234567890]表示匹配0-9中任意一个字符,记住,是一个,在regexper中图示如下:
[ahsue]表示匹配a、h、s、u、e中任意一个字符,图示如下:

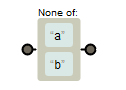
紧跟一个尖括号“^”(此时^不再是匹配位置的元字符),将会对字符集取反。结果是字符集将匹配任何不在方括号中的字符,如:[^ab]表示匹配不含a或b的字符串:
“–”在字符集中可代表范围,如[a-z]表示匹配a、b、c..x、y、z,26字母中的任意一个,[0-9]表示匹配0,1,2,3,4,5,6,7,8,9十个字符中任意一个,等效于[0123456789]。需要注意的是横线符号“-”在“[”开始的第一个字符时,它不再具有范围的特殊意义,而是一个普通字符,如[-23]匹配“-”,“2”,“3”三个字符中任意一个。
我们常用的一些特殊字符,就是字符集的简写,这也是我为什么不把这些特殊字符归为元字符的原因:
\d 代表 [0-9] \w 代表单词字符.这个是随正则表达式实现的不同而有些差异。绝大多数的正则表达式实现的单词字符集都包含了A-Za-z0-9_(单词定义为Unidcode的字母数字或下划线字符) \s 代表“空白字符”。这个也是和不同的实现有关的。在绝大多数的实现中,都包含了空格符和Tab符,以及回车换行符\r\n \S [^\s] \W [^\w] \D [^\d]
只有4个 字符具有特殊含义。它们是:“] \ ^ -”。“]”代表字符集定义的结束;“\”代表转义;“^”代表取反;“-”代表范围定义。不需要转义。例如,要搜索星号或加号+,你可以用”[+]”。当然,如果你对那些通常的元字符进行转义,你的正则表达式一样会工作得很好,但是这会降低可读性。
>>

