1. 分组与向后引用
把正则表达式的一部分放在圆括号内,每个括号内的表达式就是一个组。
对于每个组,系统会自动给之一个组编号以便在后文引用,第一个编为1号,第二个为2号,以此类推。。。
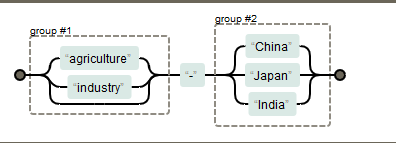
例如,对于正则表达式 (agriculture|industry)-(China|Japan|India)其结构如下:
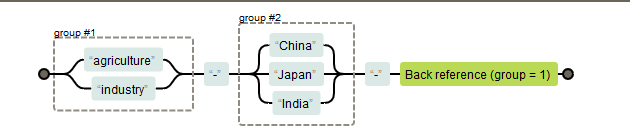
在表达式的后文,以使用\num的格式引用某个分组(其中num为正整数,表示第几个分组),如 (agriculture|industry)-(China|Japan|India)-\1,其结构变成了如下图:
(agriculture|industry)-(China|Japan|India)-\1能匹配字符串agriculture-China-agriculture:
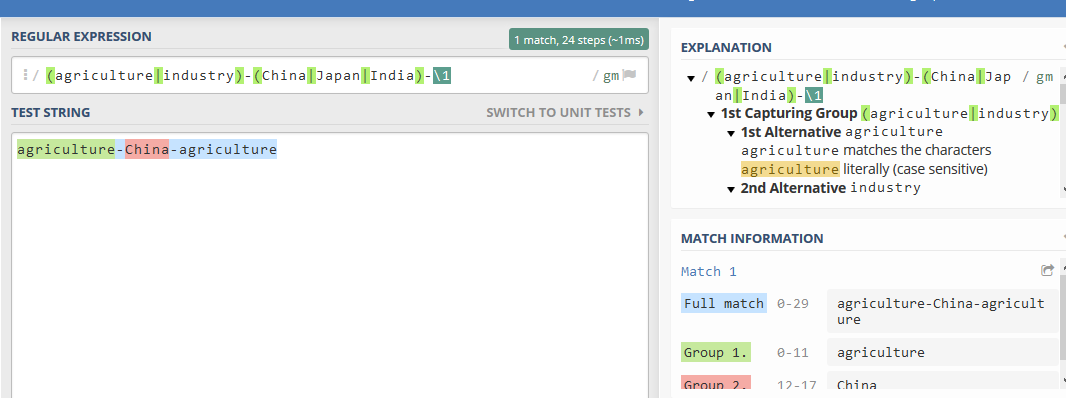
其中\1就是第一个分组的引用,以agriculture开头就必须以agriculture结束。
如果我们不想使用系统自动生成的编号,或者由于组数太多不便一个个数,可以使用给组命名的方式实现向后引用,命名格式为:
(?<groupName>expression)
引用格式为:
\k<groupName>
如有如下正则表达式,可匹配HTML的标签:
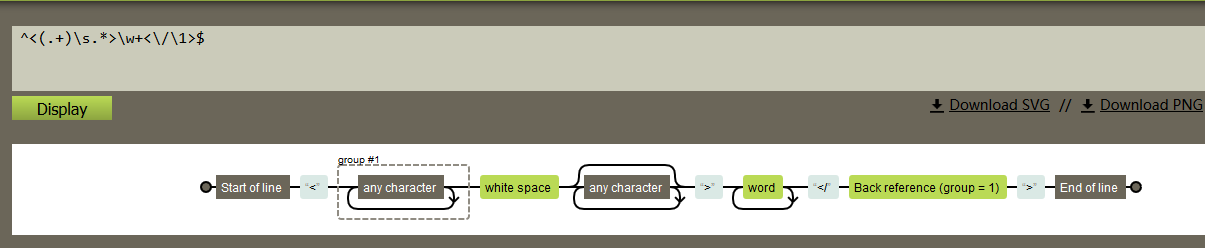
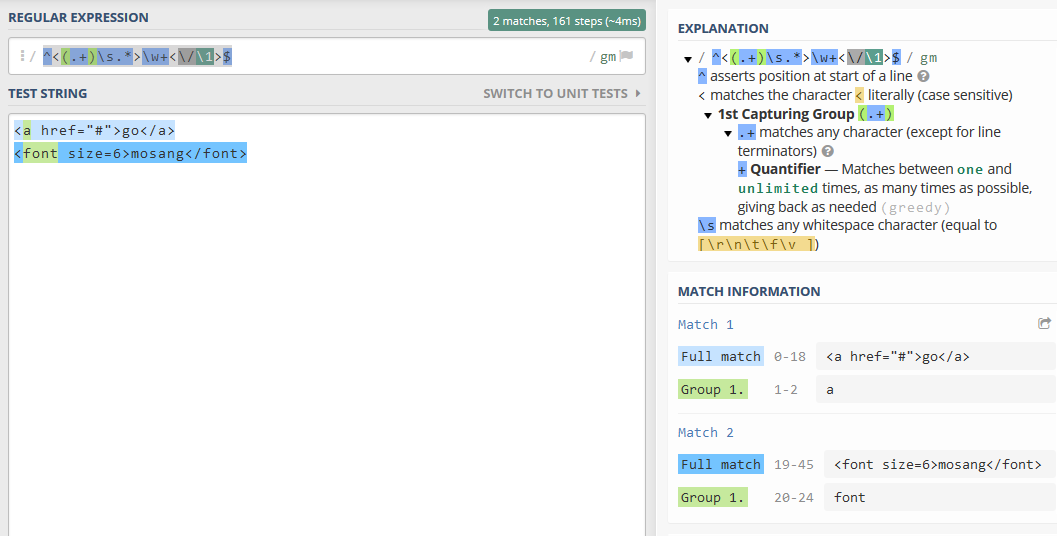
^<(.+)\s.*>\w+<\/\1>$
其中:
^ 表示行的开始 < 表示HTML的开始标签 (.+) 为标签名,如可匹配a、ul、font、...等标签名 \s 表示一个空格 .* 表示标签内的任意字符,可以匹配属性及属性值等内容 \w+ 为标签内的文字 <\/为结束标签标记 </ \1 向前引用标签名 > 封闭结束标签 $ 表示行的结束
结构如下:
匹配效果如下:
需要注意的是,不同语言实现的向后引用格式有所差异:
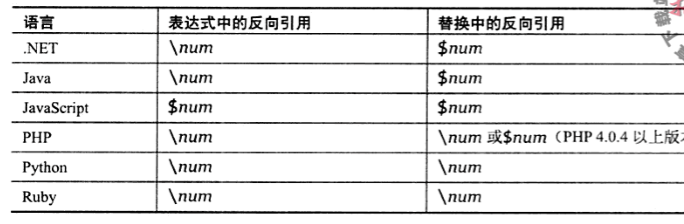
图片来源《正则指引》一书(作者:余晟)
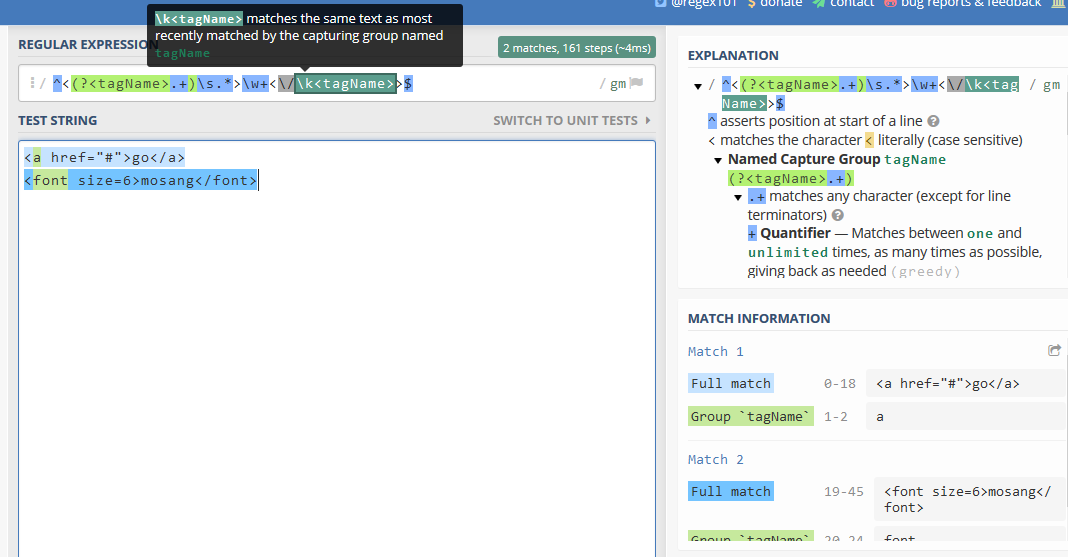
如果我们使用自命名组,那么正则表达式可更改为^<(?<tagName>.+)\s.*>\w+<\/\k<tagName>>$
可以看到匹配效果是一样的:
需要注意的是,命名分组不是正则的通用规则,不同语言支持组命名的书写格式有很大区别:

图片来源《正则指引》一书(作者:余晟)
2. 取消默认分组存储
在默认情况下,只要用()框定的内容,正则引擎就会自动分配组号,存储匹配分组,这样降低了引擎速度。如果我们不需要向后引用,可以通过(?:value)语法取消默认编组存储,其中“(”后面紧跟的“?:”会告诉引擎对于组(Value),不存储匹配的值以供后向引用。
如([0-9a-z]*)-(?:\d+),明确了第二个分组不进行编号存储,不提供向后引用。
>>

