
作用:在Think in java 系列书籍以及网上大量的文章都写了其各种各样的好处,我认为言过其实,我们用静态工厂方法,主要原因在于可以根据逻辑需求返回实例对象。可以方便实现工厂模式、单例模式。其它如,有语义方法名、返回其返回类型的任何子类型的对象,方便创建参数化类型实例等等都是无关痛痒的东西。
实现:
将创建实例封装在一个工厂类的静态方法中,静态方法不同的参数返回不同的实例。
示例:
如下所示,电脑工厂类,通过提供静态方法getComputer(String Brand)生产不同品牌的电脑(返回Computer实例对象),客户端只需要调用静态工厂方法传入不同参数即可获得目标对象。

package staticfactory;
public interface Computer {
public abstract void cal();
}
package staticfactory;
public class Mac implements Computer {
@Overrid
public void cal() {
System.out.println("苹果电脑启动。。。。");
}
}
package staticfactory;
public class HP implements Computer {
@Override
public void cal() {
System.out.println("惠普电脑启动。。。。");
}
}
package staticfactory;
public class ComputerFactory {
public static Computer getComputer(String computerBrand) {
switch (computerBrand) {
case "Mac":
return new Mac();
case "HP":
return new HP();
default:
return null;
}
}
}
package staticfactory;
public class Client {
public static void main(String[] args) {
Computer computer = ComputerFactory.getComputer("Mac");
Computer computer2 = ComputerFactory.getComputer("HP");
computer.cal();
computer2.cal();
}
}
运行结果:
苹果电脑启动。。。。 惠普电脑启动。。。。
一.开闭原则

实现方式:
1. 遵循“抽象约束、封装变化”原则,通过接口或者抽象类为实体定义一个相对稳定的抽象层,而将相同的可变因素封装在相同的具体实现类中。
2.参数类型、引用对象尽量使用接口或者抽象类,而不是实现类。
3.缩小功能颗粒度。功能粒度越小,被复用的可能性就越大,重复利用可能性就越高。
二. 里氏替换原则

简单地说,把父类都替换成它的子类,程序的行为没有变化。只要出现父类的地方,均可用子类替换,而且对整体实现并没有任何影响,提高代码的复用性。
实现方式:
子类继承父类时,除添加新的方法完成新增功能外,尽量不要重写父类的方法。
三. 依赖倒置原则

——高层模块不应该依赖低层模块,两者都应该依赖其抽象
——抽象不应该依赖细节
——细节应该依赖抽象
实现方式:
1.每个类尽量提供接口或抽象类,或者两者都具备。
2.变量的声明类型尽量是接口或者是抽象,模块间的依赖通过抽象发生,实现类之间不发生直接的依赖关系,其依赖关系是通过接口或抽象类产生的。
3.任何类都不应该从具体类派生。
4.尽量不要重写基类已经写好的方法(符合里氏替换原则)。
设计模式实质上并没有新的东西,只是一种思想体现,来来去去都是在围绕继承、多态、静态之间做文章。很多人学设计模式很吃力,被其中类之间复杂的引用关系绕晕,我认为掌握设计模式最重要的一步就是把常见类之间关系梳理出来,而UML早已经帮我们做了,拿来理顺即可。
一. 依赖关系Dependency
依赖关系是一种临时关系、使用的弱关系,是耦合度最低的一种关系。
代码表现:一个类的方法通过局部变量、方法的参数或者对静态方法的调用来访问另一个类(被依赖类)。下例中,猎人(Hunter)和枪(Gun)之间是一种使用关系,猎人使用枪进行射击,枪Gun作为一个参数出现在猎人shoot方法中(Hunter类中猎杀动作shoot()调用了Gun实例的开火fire()方法):
package com.mosang.umlmodule;
public class Hunter {
private String name;
public void shoot(Gun g) {
g.fire();
}
}
package com.mosang.umlmodule;
public class Gun {
private String brand;
public void fire() {
System.out.println("shoot.....");
}
}
package com.mosang.umlmodule;
public class Client {
public static void main(String[] args) {
Hunter hunter = new Hunter();
hunter.shoot(new Gun());
}
}
UML图示:

二. 关联关系Association
关联关系是对象之间的一种引用关系,用于表示一类对象与另一类对象之间的联系,如学生与老师、公司与员工、宠物与主人等等,存在一对一,一对多,多对多等关系。
代码表现:一个类的对象作为另一个类的成员变量。下例中学生与老师是一种多对多的关系(一个学生同时有多个老师教,一个老师也同时教多个学生),Student类作为成员变量出现在Teacher类中,Teacher类也作为成员变量出现在Student类中:
package com.mosang.umlmodule;
import java.util.List;
public class Student {
private String name;
private List<Teacher> teachers;
public void study() {
}
}
package com.mosang.umlmodule;
import java.util.List;
public class Teacher {
private String name;
private List<Student> students;
public void teach() {
}
}
UML图示:

【双向的关联可以用带两个箭头或者没有箭头的实线来表示,单向的关联用带一个箭头的实线来表示,箭头从使用类指向被关联的类。也可以在关联线的两端标注角色名,代表两种不同的角色。】 (更多…)
java中,静态方法属于类,直接使用”类名.静态方法”方式访问,也可以通过”实例.方法”访问,后者一般不推荐,但是也是合法的:
package com.mosang.staticInheri;
public class Fu {
public String a="fu";
public void ordinaryMethod() {
System.out.println("Fu ordinaryMethod");
}
public static void staticMethod() {
System.out.println("Fu static method");
}
}
package com.mosang.staticInheri;
public class Demo {
public static void main(String[] args) {
Fu f=new Fu();
f.staticMethod();//使用实例方式访问
Fu.staticMethod();//使用类名直接访问
}
}
输出如下:
Fu static method Fu static method
需要注意的是,在存在静态方法情况下的继承,静态方法不能被子类覆盖,即使子类有与父类相同的静态方法(同覆盖规则),也不是覆盖重写,如有Zi类继承如下:
package com.mosang.staticInheri;
public class Zi extends Fu{
public String a="zi";
public void ordinaryMethod() {
System.out.println("Zi ordinaryMethod"); //实例方法,覆盖重写
}
public static void staticMethod() {
System.out.println("Zi static method"); //与父类相同的静态方法(方法名、返回值、参数均相同)
}
}
通过两种方式创建子类实例:
package com.mosang.staticInheri;
public class Demo {
public static void main(String[] args) {
Fu f1=new Zi();//多态方式创建对象
Zi f2=new Zi();//普通方式创建对象
f1.ordinaryMethod(); //输出Zi ordinaryMethod
f1.staticMethod();//输出Fu static method
f2.ordinaryMethod();//Zi ordinaryMethod
f2.staticMethod();//Zi static method
}
}
输出结果
Zi ordinaryMethod Fu static method Zi ordinaryMethod Zi static method
从上输出结果可看到,父类的静态方法并不能被覆盖,只是被隐藏。
同样,静态成员变量也是一样的道理。出现相同静态字段时父类字段不会将子类字段覆盖,而只是将其“隐藏”。
1.运算符优先级
默认情况下,和算术表达式类似,正则表达式按照从左到右顺序计算或匹配,相同优先级的从左到右进行运算,不同优先级的运算先高后低。
从高到低各种正则表达式运算符的优先级如下所示(注:表格数据来源于w3school):
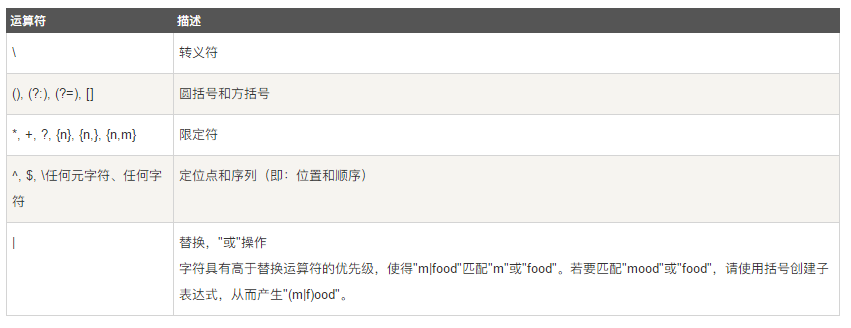
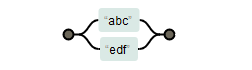
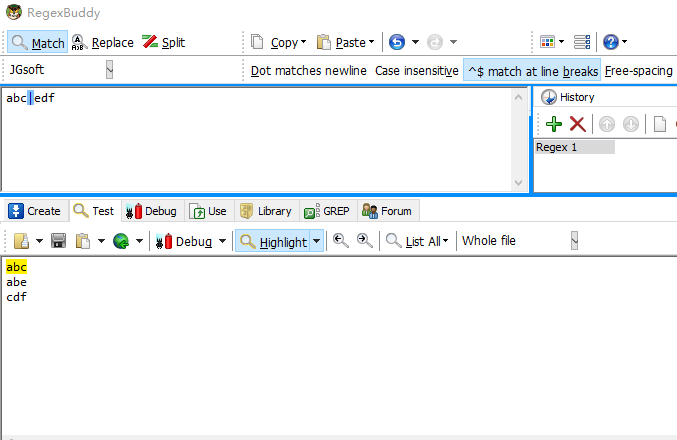
或运算符(也称为选择运算符)最低的优先级,也就是说,它告诉引擎要么匹配选择符左边的所有表达式,要么匹配右边的所有表达式。
比如有正则表达式 abc|edf,按照优先级,它要么匹配abc要么匹配edf,而不是在c和e之间择其一。
2. 零宽度断言
正则表达式中,有一类是标明位置而不匹配具体字符的特殊标识符。
1. 数量限定符
数量限定符用来指定其紧邻的前表达式的出现次数,数量限定符主要有如下:

以上表格是多数书籍或网上教程对限定符的释义。其中最容易令人产生疑惑的“重复”二字,初学者往往理解为相同内容出现次数,个人认为这个词用得很不好。
对于正则表达式 \d{3},等同于\d\d\d,但用“重复”来强调,容易让人理解为相同结果重复三次,类似于(\d)\1\1的效果。
举例来说,\d{3},匹配123、673、222,但(\d)\1\1只能匹配这三个字符串中的222。而很多初学者往往理解“重复”为后者。
所以,有必要强调,限定符的重复次数是指表达式重复而不是结果重复。
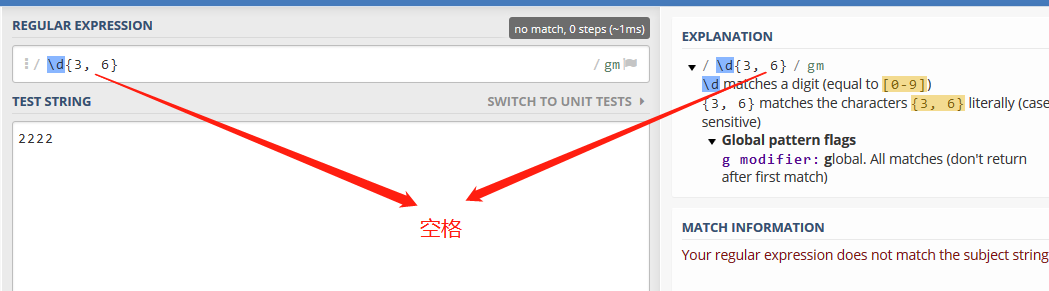
值得注意的是,上下限限定符可以有{n}、{n,m}、{n,}等形式,但是不存在{,m}这种形式,这是一种错误的写法。另外,上下限量词与逗号之间不能有空格,如\d{3, 6}是错误的写法,将无法实现目标匹配:
2.贪婪模式与懒惰模式
“{m,n}”、“{m,}”、“?”、“*”和“+” 为贪婪模式的限定词,也叫做匹配优先量词。被匹配优先量词修饰的子表达式使用的就是贪婪模式,如“(Exp)+”。
在匹配优先量词后加上“?”,即变成属于非贪婪模式的量词,也叫做忽略优先量词,包括:
“{m,n}?”、“{m,}?”、“??”、“*?” 与 “+?”
贪婪模式总是试图尽可能多地匹配目标字符串,如以下HTML代码:
abc<p>第一段</p><p>第二段</p><p>第三段</p>def
我们用正则<p>.*</p> 去匹配

这是一种贪婪模式的匹配得到的匹配结果为:
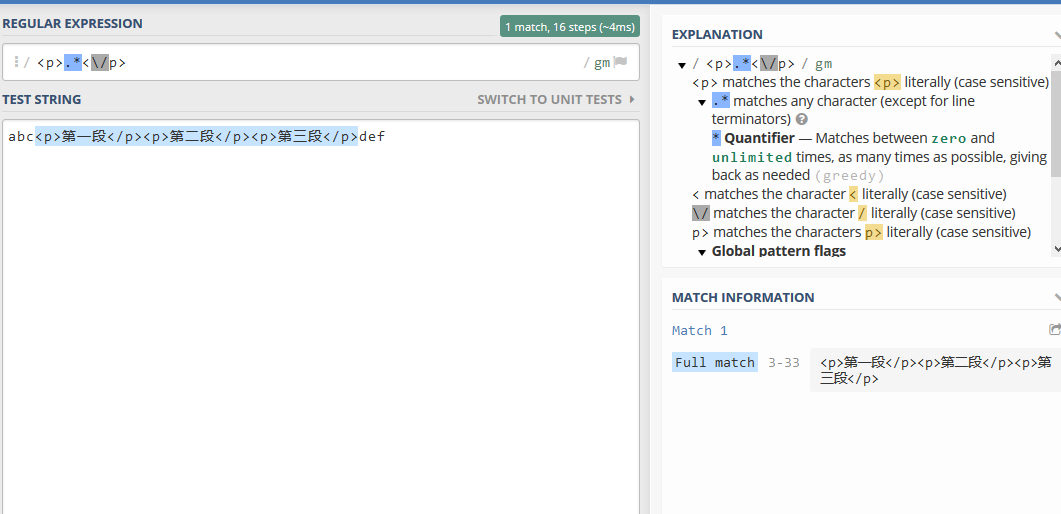
贪婪模式下它会选定尽可能多的内容,如果 失败则回退一个字符,然后再次尝试回退的过程就叫做回溯,它会每次回退一个字符,直到找到匹配的内容或者没有字符可以回退。用通俗一点的话来说,在拿不准是否要匹配的情况下,优先尝试匹配,并记下这个状态,以备将来“后悔”(也就是回溯)。
我们把正则更改为<p>.*?</p> ,匹配结果如下:
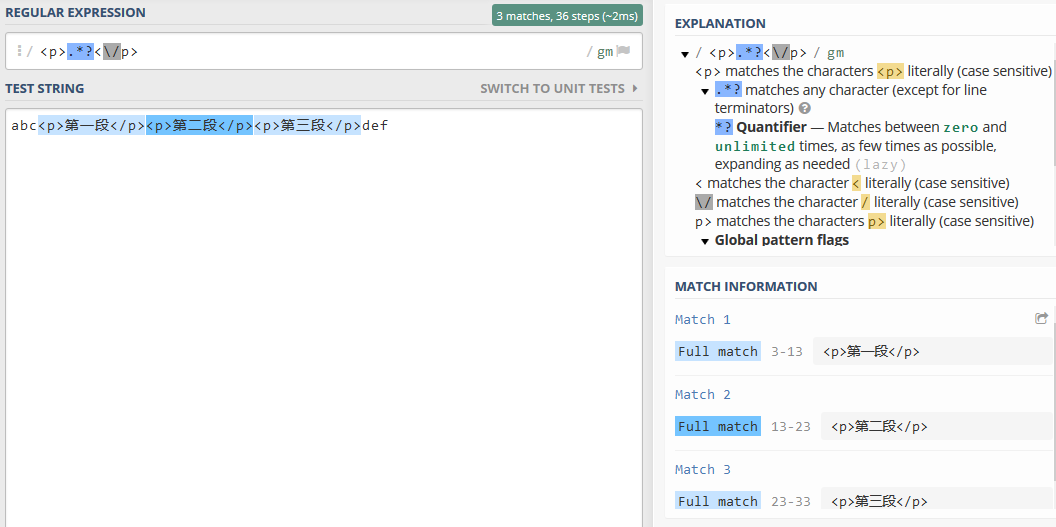
可以看到,在懒惰模式下,它会尽可能少地重复限定量,只要匹配到一个就返回了结果。
我们再更改下正则:<p>.*?</p>def,再看匹配结果:
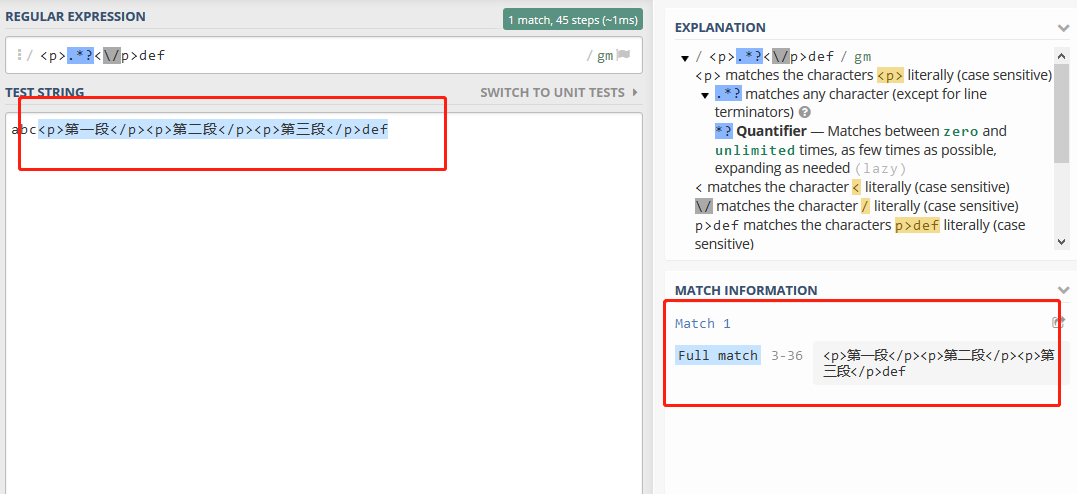
可以看到,在“整个表达式匹配成功”的前提下,非贪婪模式才真正的影响着子表达式的匹配行为,如果整个表达式匹配失败,非贪婪模式无法影响子表达式的匹配行为。
1. 分组与向后引用
把正则表达式的一部分放在圆括号内,每个括号内的表达式就是一个组。
对于每个组,系统会自动给之一个组编号以便在后文引用,第一个编为1号,第二个为2号,以此类推。。。
例如,对于正则表达式 (agriculture|industry)-(China|Japan|India)其结构如下:
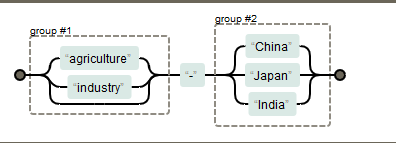
在表达式的后文,以使用\num的格式引用某个分组(其中num为正整数,表示第几个分组),如 (agriculture|industry)-(China|Japan|India)-\1,其结构变成了如下图:
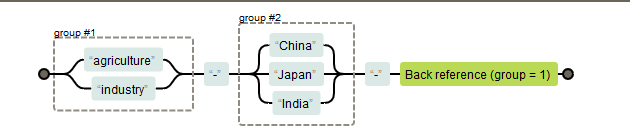
(agriculture|industry)-(China|Japan|India)-\1能匹配字符串agriculture-China-agriculture:
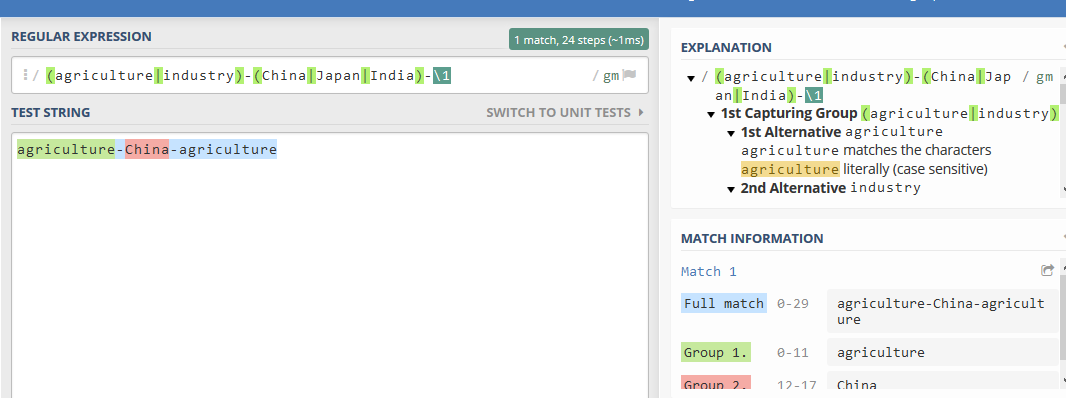
其中\1就是第一个分组的引用,以agriculture开头就必须以agriculture结束。
如果我们不想使用系统自动生成的编号,或者由于组数太多不便一个个数,可以使用给组命名的方式实现向后引用,命名格式为:
(?<groupName>expression)
引用格式为:
\k<groupName>
如有如下正则表达式,可匹配HTML的标签:
^<(.+)\s.*>\w+<\/\1>$
其中:
^ 表示行的开始 < 表示HTML的开始标签 (.+) 为标签名,如可匹配a、ul、font、...等标签名 \s 表示一个空格 .* 表示标签内的任意字符,可以匹配属性及属性值等内容 \w+ 为标签内的文字 <\/为结束标签标记 </ \1 向前引用标签名 > 封闭结束标签 $ 表示行的结束
结构如下:
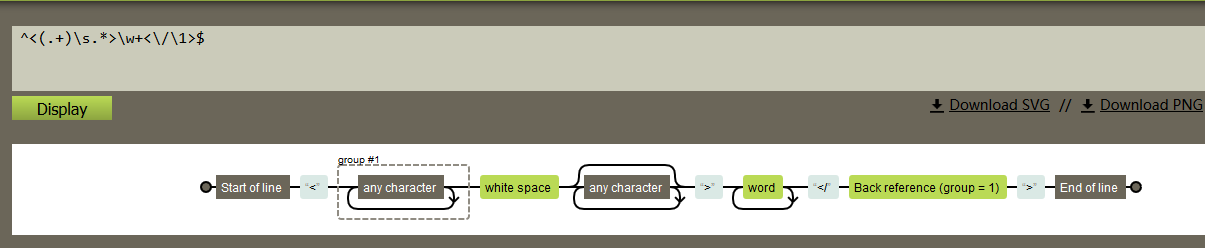
匹配效果如下:
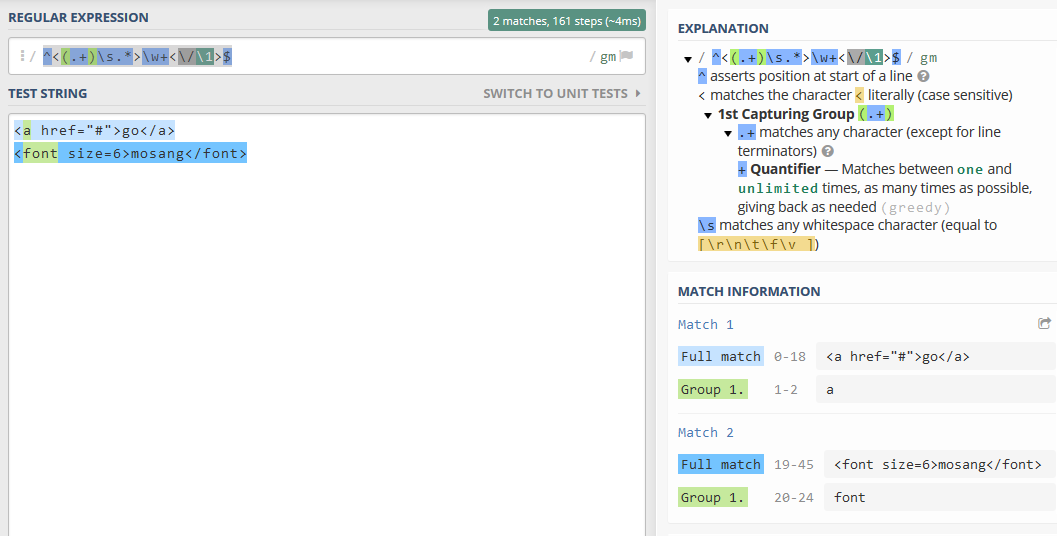
需要注意的是,不同语言实现的向后引用格式有所差异:
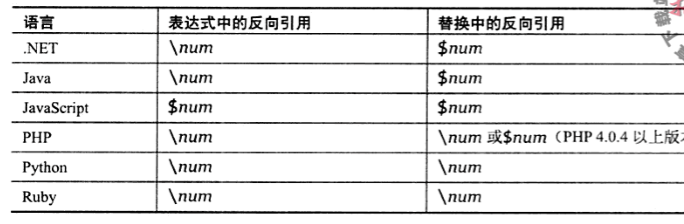
图片来源《正则指引》一书(作者:余晟)
如果我们使用自命名组,那么正则表达式可更改为^<(?<tagName>.+)\s.*>\w+<\/\k<tagName>>$
可以看到匹配效果是一样的:
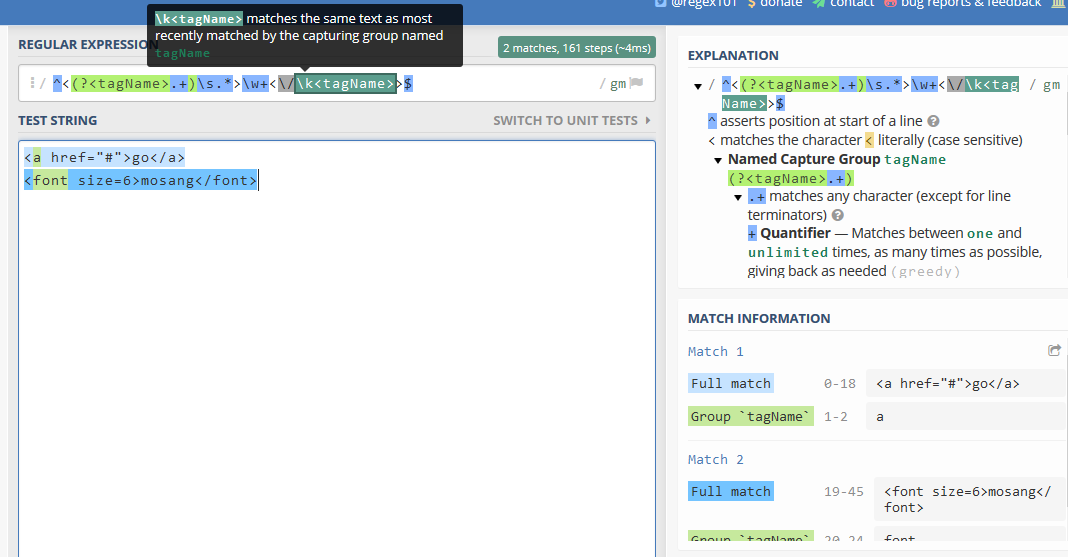
需要注意的是,命名分组不是正则的通用规则,不同语言支持组命名的书写格式有很大区别:

图片来源《正则指引》一书(作者:余晟)
2. 取消默认分组存储
在默认情况下,只要用()框定的内容,正则引擎就会自动分配组号,存储匹配分组,这样降低了引擎速度。如果我们不需要向后引用,可以通过(?:value)语法取消默认编组存储,其中“(”后面紧跟的“?:”会告诉引擎对于组(Value),不存储匹配的值以供后向引用。
如([0-9a-z]*)-(?:\d+),明确了第二个分组不进行编号存储,不提供向后引用。

