字符集
字符集是由一对方括号“[]”括起来的字符集合。表示匹配[]包含的多个中的其中一个。
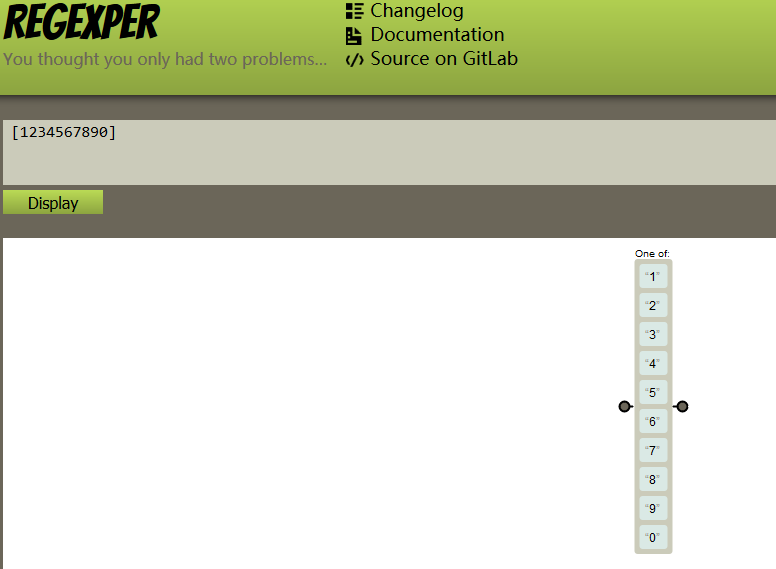
[1234567890]表示匹配0-9中任意一个字符,记住,是一个,在regexper中图示如下:
[ahsue]表示匹配a、h、s、u、e中任意一个字符,图示如下:

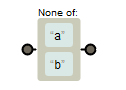
紧跟一个尖括号“^”(此时^不再是匹配位置的元字符),将会对字符集取反。结果是字符集将匹配任何不在方括号中的字符,如:[^ab]表示匹配不含a或b的字符串:
“–”在字符集中可代表范围,如[a-z]表示匹配a、b、c..x、y、z,26字母中的任意一个,[0-9]表示匹配0,1,2,3,4,5,6,7,8,9十个字符中任意一个,等效于[0123456789]。需要注意的是横线符号“-”在“[”开始的第一个字符时,它不再具有范围的特殊意义,而是一个普通字符,如[-23]匹配“-”,“2”,“3”三个字符中任意一个。
我们常用的一些特殊字符,就是字符集的简写,这也是我为什么不把这些特殊字符归为元字符的原因:
\d 代表 [0-9] \w 代表单词字符.这个是随正则表达式实现的不同而有些差异。绝大多数的正则表达式实现的单词字符集都包含了A-Za-z0-9_(单词定义为Unidcode的字母数字或下划线字符) \s 代表“空白字符”。这个也是和不同的实现有关的。在绝大多数的实现中,都包含了空格符和Tab符,以及回车换行符\r\n \S [^\s] \W [^\w] \D [^\d]
只有4个 字符具有特殊含义。它们是:“] \ ^ -”。“]”代表字符集定义的结束;“\”代表转义;“^”代表取反;“-”代表范围定义。不需要转义。例如,要搜索星号或加号+,你可以用”[+]”。当然,如果你对那些通常的元字符进行转义,你的正则表达式一样会工作得很好,但是这会降低可读性。
1. 12个元字符
学正则之前,你肯定翻过很多正则的书籍,被它们介绍的一大堆元字符搞得头大,如\d,\w,^,\A,$,\f……等等几十个,不仅难记而且容易混淆。实际上真正称得上元字符的只有12个,没错,对于元字符,你只需要记住这十二个:
[ ] \ ^ $ . | ? * + ( )
对于这12个元字符,如果你想在正则表达式中将这些字符用作文本字符,你需要用反斜杠“\”对其进行换码 (escape)也称为转义。
—— [] 表示一个字符集。
—— \ 有多重含义。一般情况下表示转义,或特殊字符的开始。如\d,这两个字符在一起,是一个整体,有特殊的含义,表示一个数字。如果与正整数连在一起用,表示向后引用,如\1表示引用第一个分组。
—— ^ 有多重含义。表达式开头位置表示输入字符串的开始位置,在字符集开始的位置中表示取反。
—— $ 表示输入字符串的结束位置。
—— | 逻辑“或”运算符,表示在多个条件中择其一。
—— ? 有多重含义。跟在表达式后,表示量词限定词0次或1次,如\d?;跟在量词限定词后,表示非贪婪模式,如\w{3,5}?;跟在括号开始位置表示特殊指令,如(?=pattern)、(?!pattern)、(?:pattern)、(?<!pattern)等表示零宽度断言,而(?m)放在在整个正则表达式前面,表示采用“多行模式”。
—— * 量词限定词,表示前面的子表达式可出现任意次。
—— + 量词限定词,表示前面的子表达式至少出现一次。
—— ( ) 有多重含义。一般表示表达式分组,与?连用有特殊指令,如(?=pattern)、(?:pattern)
2. 特殊字符
除了12个元字符外,其它有特殊含义字符我称之为特殊字符或简易字符。特殊字符是由转义字符与普通字符结合,形成有特殊含义的一类标识符,如:
|
\d
|
匹配一个数字字符。等价于[0-9]。
|
|
\D
|
匹配一个非数字字符。等价于[^0-9]。
|
|
\f
|
匹配一个换页符。等价于\x0c和\cL。
|
|
\n
|
匹配一个换行符。等价于\x0a和\cJ。
|
|
\r
|
匹配一个回车符。等价于\x0d和\cM。
|
|
\s
|
匹配任何不可见字符,包括空格、制表符、换页符等等。等价于[ \f\n\r\t\v]。
|
|
\S
|
匹配任何可见字符。等价于[^ \f\n\r\t\v]。
|
|
\t
|
匹配一个制表符。等价于\x09和\cI。
|
|
\v
|
匹配一个垂直制表符。等价于\x0b和\cK。
|
|
\w
|
匹配包括下划线的任何单词字符。类似但不等价于“[A-Za-z0-9_]”,这里的”单词”字符使用Unicode字符集。
|
|
\W
|
匹配任何非单词字符。等价于“[^A-Za-z0-9_]”。
|
|
\xn
|
匹配n,其中n为十六进制转义值。十六进制转义值必须为确定的两个数字长。例如,“\x41”匹配“A”。“\x041”则等价于“\x04&1”。正则表达式中可以使用ASCII编码。
|
|
\num
|
匹配num,其中num是一个正整数。对所获取的匹配的引用。例如,“(.)\1”匹配两个连续的相同字符。
|
|
\n
|
标识一个八进制转义值或一个向后引用。如果\n之前至少n个获取的子表达式,则n为向后引用。否则,如果n为八进制数字(0-7),则n为一个八进制转义值。
|
|
\nm
|
标识一个八进制转义值或一个向后引用。如果\nm之前至少有nm个获得子表达式,则nm为向后引用。如果\nm之前至少有n个获取,则n为一个后跟文字m的向后引用。如果前面的条件都不满足,若n和m均为八进制数字(0-7),则\nm将匹配八进制转义值nm。
|
|
\nml
|
如果n为八进制数字(0-7),且m和l均为八进制数字(0-7),则匹配八进制转义值nml。
|
|
\un
|
匹配n,其中n是一个用四个十六进制数字表示的Unicode字符。例如,\u00A9匹配版权符号(©)。
|
特殊字符代表的含义在w3school等网站都可以查到,这里就不做过多介绍。
1. 关于“匹配”一词的理解。
这是正则表达式用的最多的词,但是这个词对于初学者常常给人忽远忽近的感觉,有时候感觉理解了,有时候又觉得被绕进去了,离真正理解还很远。
我们在windows电脑上搜索文件,比如要搜所有MP4格式的视频,可以在搜索栏中输入“*.MP4”,搜索出来的文件就是mp4视频文件,假设搜索结果如下:
精通java.mp4 战狼2.MP4 三国央视版.MP4
用正则词汇来说,“*.MP4”匹配“精通java.mp4”、“战狼2.MP4”、“三国央视版.MP4”等字符串。
用我们通俗的话来说,“*”字符能代表“精通java”、“战狼2”、“三国央视版”等字符串,匹配就是这个正则表达式能代表这个字符串。
匹配结果,就是按照正则表达式的规则,在字符串中能不能找到符合此规则的字符串,能找到多少个字符串。如果不能找到称为不匹配,如果能找到一个或者多个,则每一个都称为一个匹配。
匹配这个词之所以常常令人费解,那是因为很多书把这个词义经常混淆一起用,把初学者搞晕了。
匹配有三种形式的存在:
——形容词性质的匹配:一个字符串“契合”一个正则,用于判断输出true或false。
——动词性质的匹配:在字符串中搜索符合正则的字符串。
——名词性质的匹配:字符串中满足正则的一部分,每一个部分都称为一个匹配。
这几个混在一起,很容易把人搞懵了。其实你只需要记住,匹配就是根据正则表达式这个“规则”,能在字符串中找到子字符串,就是匹配,就是这么简单。
2. 关于字符串的理解
正则表达式是判断、搜索字符串的专门语言,处理的一切对象都是字符串(文本也是字符串的一种,只不过包含换行等特殊符号而已),没有其他数据类型之分。
比如,对“18790”,我们在其它语言如C、Java、PHP中会认为这是一个数字,是一个整体,但是在正则中,它只是由5个数字组成的字符串,对,只是字符串而已,和“abcde”性质是一样的,并非一整数。
在正式进入正则学习之前,先安利几个好用的校验和测试工具:
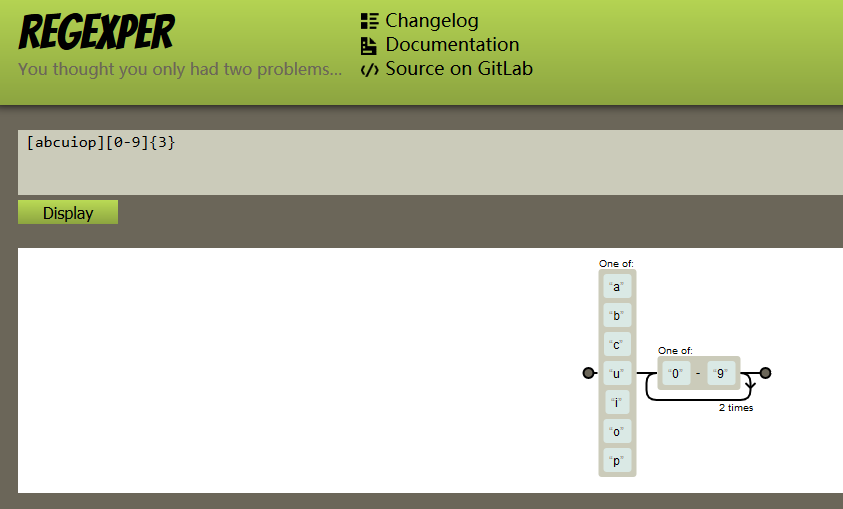
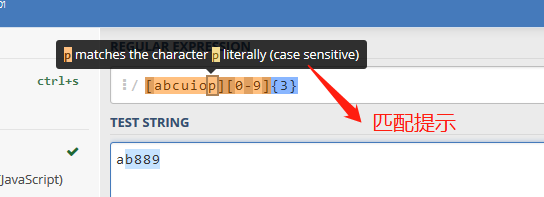
1. 在线正则结构分析工具 regexper。
regexper以直观的图例展现正则的结构,对分析和编写正则非常有帮助。
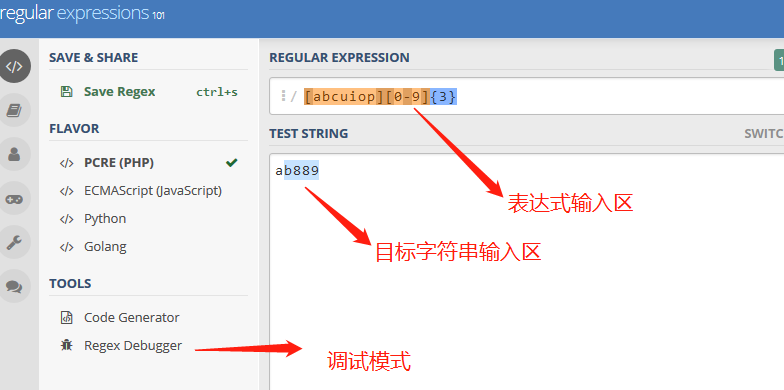
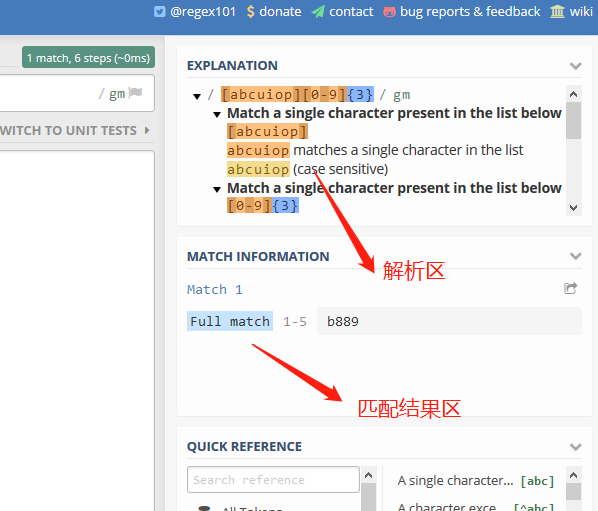
2. 正则在线测试工具regex101
regex101使用无需注册,打开即用。它不仅能快速响应匹配结果,设定各种匹配模式,还具有动态展现匹配过程功能的调试模式,对匹配过程以动画形式展现,是一款很赞的正则引擎。

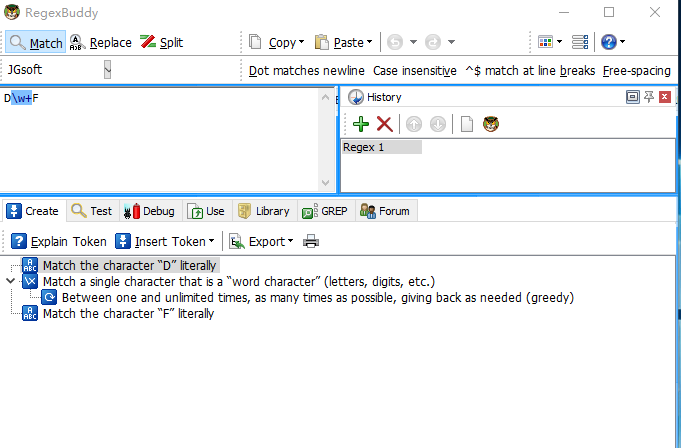
3. 本地正则测试工具RegexBuddy
这是一个比较经典的正则工具,官网地址:http://www.regexbuddy.com/
RegexBuddy是个收费软件,不过网上有很多和谐版的下载,各位自行找度娘要吧。
近期为大数据分析部门培训Excel高级运用,涉及到正则、SQL、VBA的运用,借此备讲机会写一个想了很久但没做的正则教程。
市面上的正则表达式书籍琳琅满目,包括很多命名为《精通正则表达式》《深入浅出学习正则表达式》《正则表达式从入门到精通》《XX天精通正则表达式》…的书籍, 但真正能做到浅显易懂的寥寥无几。正则本身语言结构不友好,逻辑抽象,很多初学者感觉非常吃力,而借助的书籍往往是以“编著”凑数的书,很难啃。
本教程力求以最简明的方式,清晰的逻辑带你全面了解正则表达式。
一.第一步:创建socket套接字。
socket_create ( int $domain , int $type , int $protocol ) : resource
创建并返回一个套接字,也称作一个通讯节点。一个典型的网络连接由 2 个套接字构成,一个运行在客户端,另一个运行在服务器端。(socket_create() 正确时返回一个套接字,失败时返回 FALSE。要读取错误代码,可调用 socket_last_error())
domain的可选参数:
AF_INET: IPv4 网络协议。TCP 和 UDP 都可使用此协议。 AF_INET6: IPv6 网络协议。TCP 和 UDP 都可使用此协议。 AF_UNIX: 本地通讯协议。具有高性能和低成本的 IPC(进程间通讯)。
type 参数用于选择套接字使用的类型,可选值有:
SOCK_STREAM 提供一个顺序化的、可靠的、全双工的、基于连接的字节流。支持数据传送流量控制机制。TCP 协议即基于这种流式套接字。 SOCK_DGRAM 提供数据报文的支持。(无连接,不可靠、固定最大长度).UDP协议即基于这种数据报文套接字。 SOCK_SEQPACKET 提供一个顺序化的、可靠的、全双工的、面向连接的、固定最大长度的数据通信;数据端通过接收每一个数据段来读取整个数据包。 SOCK_RAW 提供读取原始的网络协议。这种特殊的套接字可用于手工构建任意类型的协议。一般使用这个套接字来实现 ICMP 请求(例如 ping)。 SOCK_RDM 提供一个可靠的数据层,但不保证到达顺序。一般的操作系统都未实现此功能。
protocol参数可选值:
tcp、udp和icmp
可以看出socket_create函数的type参数和protocol参数是相关联的。
二. 第二步:开启套接字链接。
socket_connect ( resource $socket , string $address [, int $port = 0 ] ) : bool
成功时返回 TRUE, 或者在失败时返回 FALSE。 错误代码会传入 socket_last_error()
ADDRESS参数:
如果参数 socket 是 AF_INET , 那么参数 address 则可以是一个点分四组表示法(例如 127.0.0.1 ) 的 IPv4 地址; 如果支持 IPv6 并且 socket 是 AF_INET6,那么 address 也可以是有效的 IPv6 地址(例如 ::1);如果套接字类型为 AF_UNIX ,那么 address 也可以是一个Unix 套接字。
PORT参数:
仅仅用于 AF_INET 和 AF_INET6 套接字连接的时候,并且是在此情况下是需要强制说明连接对应的远程服务器上的端口号。
三. 第三步:socket_bind — 给套接字绑定名字
socket_bind ( resource $socket , string $address [, int $port = 0 ] ) : bool
绑定 address 到 socket。 该操作必须是在使用 socket_connect() 或者 socket_listen() 建立一个连接之前。
成功时返回 TRUE, 或者在失败时返回 FALSE。
四. 监听套接字:socket_listen()
….待续
PHP的MVC模式相比其他语言有快捷、简单的显式优势,其中原因之一就是PHP支持可变变量、可变函数、可变类、匿名函数等,很方便实现了动态调用。
匿名函数(闭包closures)最常用于回调,以下为官方文档的示例:
echo preg_replace_callback('~-([a-z])~', function ($match) {
return strtoupper($match[1]);
}, 'hello-world');
// 输出 helloWorld
声明匿名函数可将其赋与一个变量。PHP 会自动把此种表达式转换成内置类 Closure 的对象实例。把一个 closure 对象赋值给一个变量的方式与普通变量赋值的语法是一样的,最后也要加上分号:
$greet = function($name)
{
printf("Hello %s\r\n", $name);
}; //这里需要加分号
$greet('World');
$greet('PHP');
匿名函数可以从父作用域中继承变量。 任何此类变量都应该用 use 语言结构传递进去。 PHP 7.1 起,不能传入此类变量:superglobals、 $this 或者和参数重名。 (更多…)

