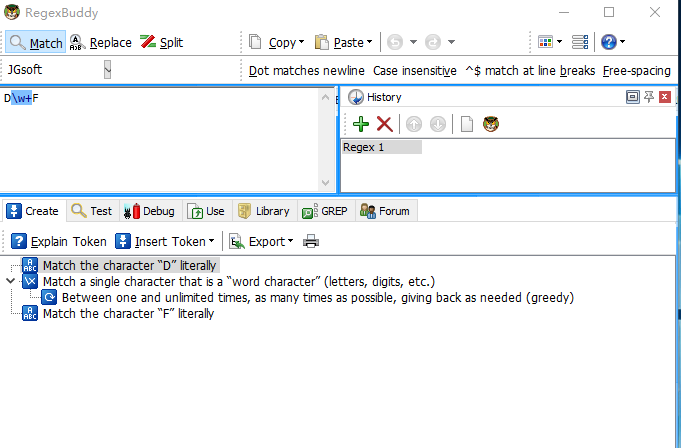
1.运算符优先级
默认情况下,和算术表达式类似,正则表达式按照从左到右顺序计算或匹配,相同优先级的从左到右进行运算,不同优先级的运算先高后低。
从高到低各种正则表达式运算符的优先级如下所示(注:表格数据来源于w3school):
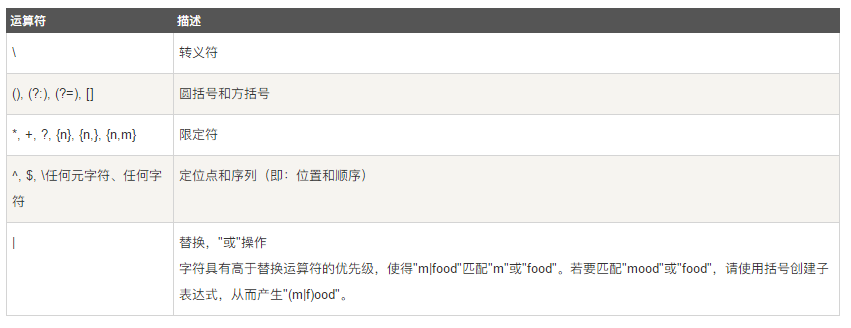
或运算符(也称为选择运算符)最低的优先级,也就是说,它告诉引擎要么匹配选择符左边的所有表达式,要么匹配右边的所有表达式。
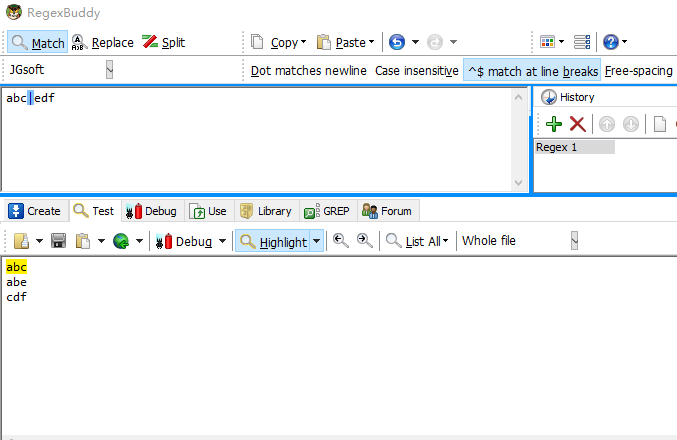
比如有正则表达式 abc|edf,按照优先级,它要么匹配abc要么匹配edf,而不是在c和e之间择其一。
2. 零宽度断言
正则表达式中,有一类是标明位置而不匹配具体字符的特殊标识符。
1. 数量限定符
数量限定符用来指定其紧邻的前表达式的出现次数,数量限定符主要有如下:

以上表格是多数书籍或网上教程对限定符的释义。其中最容易令人产生疑惑的“重复”二字,初学者往往理解为相同内容出现次数,个人认为这个词用得很不好。
对于正则表达式 \d{3},等同于\d\d\d,但用“重复”来强调,容易让人理解为相同结果重复三次,类似于(\d)\1\1的效果。
举例来说,\d{3},匹配123、673、222,但(\d)\1\1只能匹配这三个字符串中的222。而很多初学者往往理解“重复”为后者。
所以,有必要强调,限定符的重复次数是指表达式重复而不是结果重复。
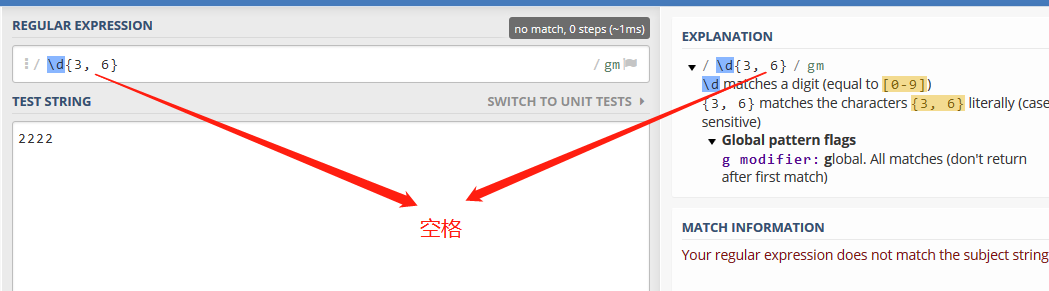
值得注意的是,上下限限定符可以有{n}、{n,m}、{n,}等形式,但是不存在{,m}这种形式,这是一种错误的写法。另外,上下限量词与逗号之间不能有空格,如\d{3, 6}是错误的写法,将无法实现目标匹配:
2.贪婪模式与懒惰模式
“{m,n}”、“{m,}”、“?”、“*”和“+” 为贪婪模式的限定词,也叫做匹配优先量词。被匹配优先量词修饰的子表达式使用的就是贪婪模式,如“(Exp)+”。
在匹配优先量词后加上“?”,即变成属于非贪婪模式的量词,也叫做忽略优先量词,包括:
“{m,n}?”、“{m,}?”、“??”、“*?” 与 “+?”
贪婪模式总是试图尽可能多地匹配目标字符串,如以下HTML代码:
abc<p>第一段</p><p>第二段</p><p>第三段</p>def
我们用正则<p>.*</p> 去匹配

这是一种贪婪模式的匹配得到的匹配结果为:
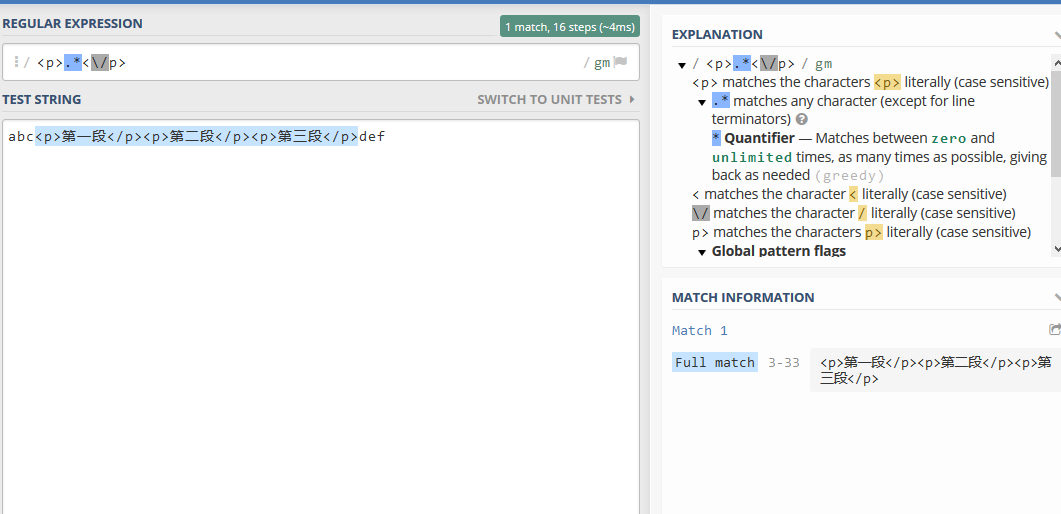
贪婪模式下它会选定尽可能多的内容,如果 失败则回退一个字符,然后再次尝试回退的过程就叫做回溯,它会每次回退一个字符,直到找到匹配的内容或者没有字符可以回退。用通俗一点的话来说,在拿不准是否要匹配的情况下,优先尝试匹配,并记下这个状态,以备将来“后悔”(也就是回溯)。
我们把正则更改为<p>.*?</p> ,匹配结果如下:
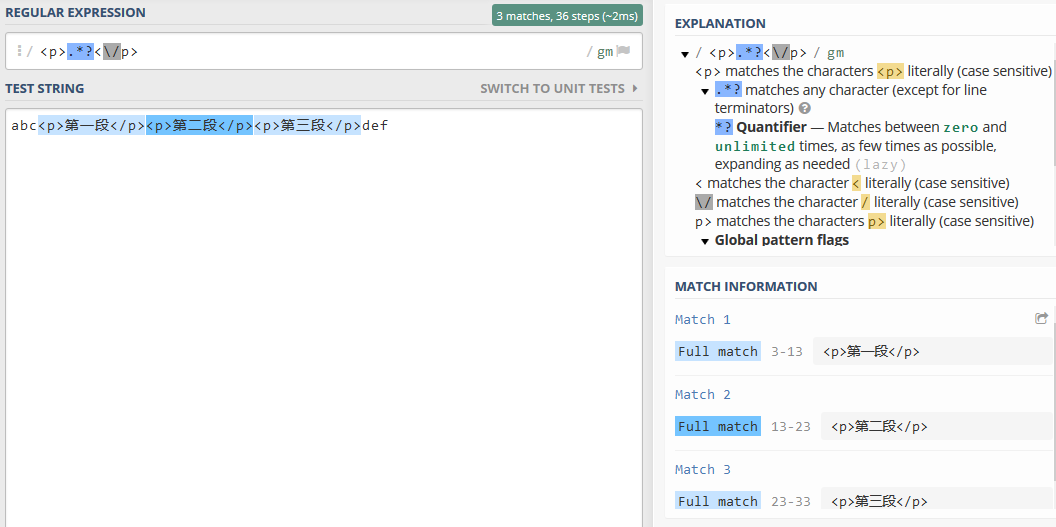
可以看到,在懒惰模式下,它会尽可能少地重复限定量,只要匹配到一个就返回了结果。
我们再更改下正则:<p>.*?</p>def,再看匹配结果:
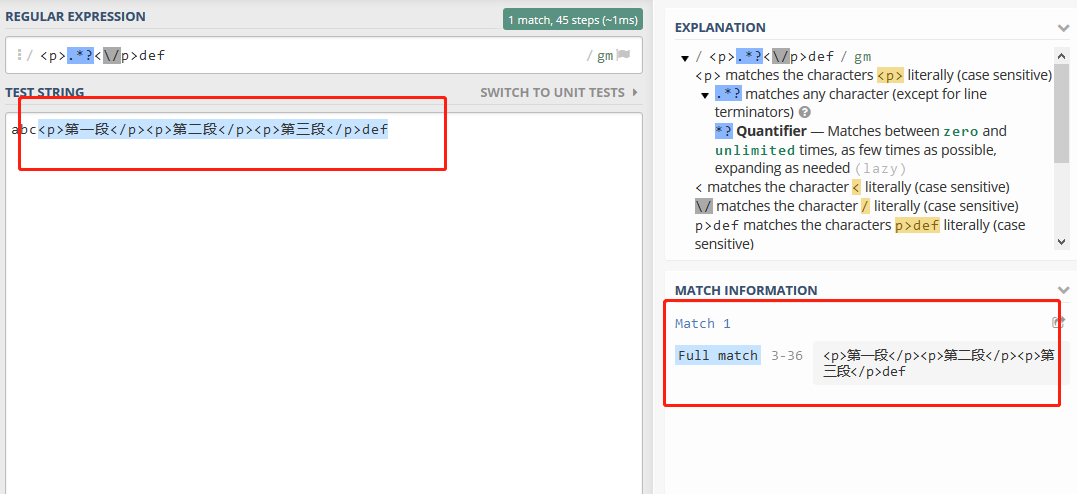
可以看到,在“整个表达式匹配成功”的前提下,非贪婪模式才真正的影响着子表达式的匹配行为,如果整个表达式匹配失败,非贪婪模式无法影响子表达式的匹配行为。
1. 分组与向后引用
把正则表达式的一部分放在圆括号内,每个括号内的表达式就是一个组。
对于每个组,系统会自动给之一个组编号以便在后文引用,第一个编为1号,第二个为2号,以此类推。。。
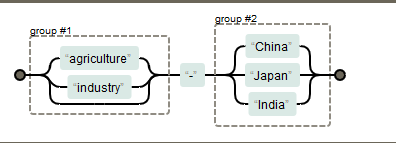
例如,对于正则表达式 (agriculture|industry)-(China|Japan|India)其结构如下:
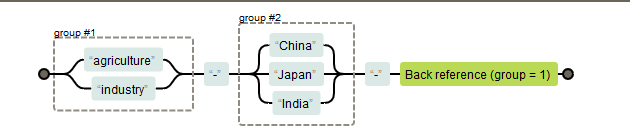
在表达式的后文,以使用\num的格式引用某个分组(其中num为正整数,表示第几个分组),如 (agriculture|industry)-(China|Japan|India)-\1,其结构变成了如下图:
(agriculture|industry)-(China|Japan|India)-\1能匹配字符串agriculture-China-agriculture:
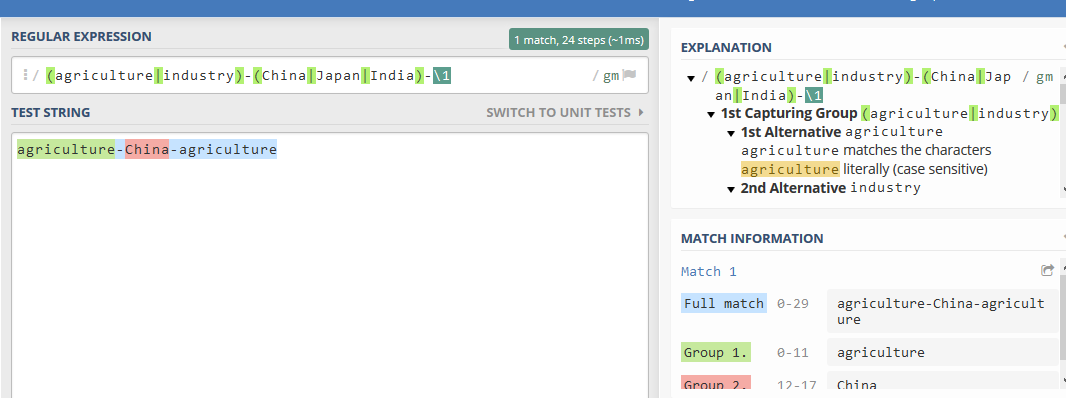
其中\1就是第一个分组的引用,以agriculture开头就必须以agriculture结束。
如果我们不想使用系统自动生成的编号,或者由于组数太多不便一个个数,可以使用给组命名的方式实现向后引用,命名格式为:
(?<groupName>expression)
引用格式为:
\k<groupName>
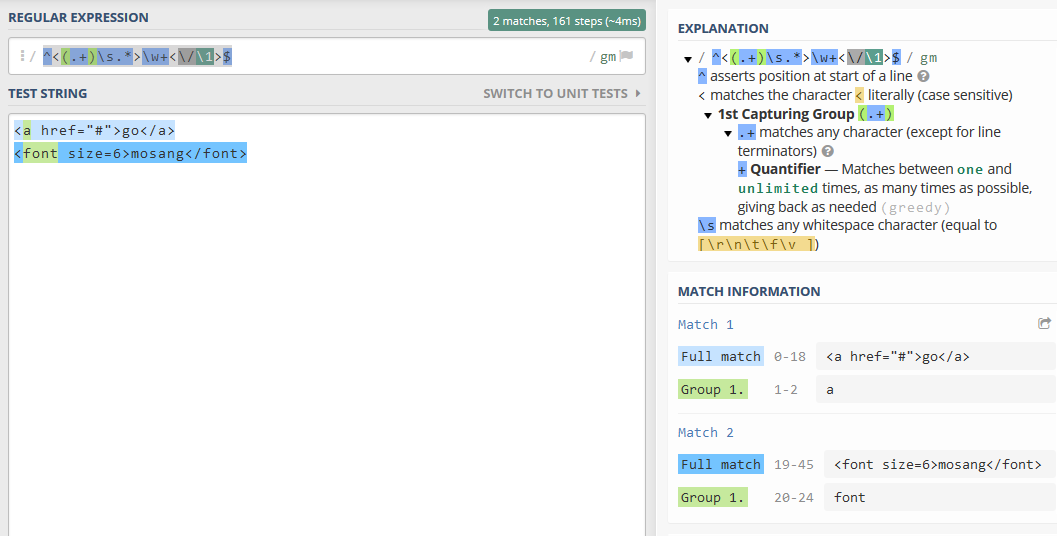
如有如下正则表达式,可匹配HTML的标签:
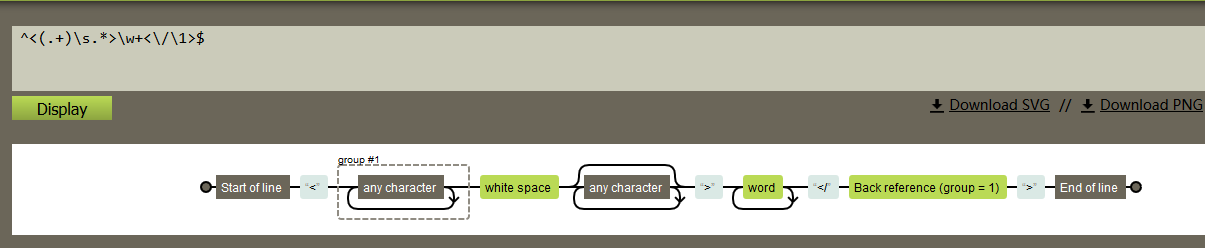
^<(.+)\s.*>\w+<\/\1>$
其中:
^ 表示行的开始 < 表示HTML的开始标签 (.+) 为标签名,如可匹配a、ul、font、...等标签名 \s 表示一个空格 .* 表示标签内的任意字符,可以匹配属性及属性值等内容 \w+ 为标签内的文字 <\/为结束标签标记 </ \1 向前引用标签名 > 封闭结束标签 $ 表示行的结束
结构如下:
匹配效果如下:
需要注意的是,不同语言实现的向后引用格式有所差异:
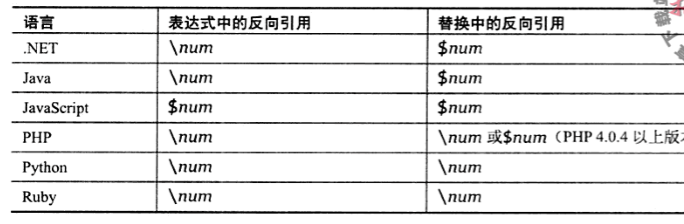
图片来源《正则指引》一书(作者:余晟)
如果我们使用自命名组,那么正则表达式可更改为^<(?<tagName>.+)\s.*>\w+<\/\k<tagName>>$
可以看到匹配效果是一样的:
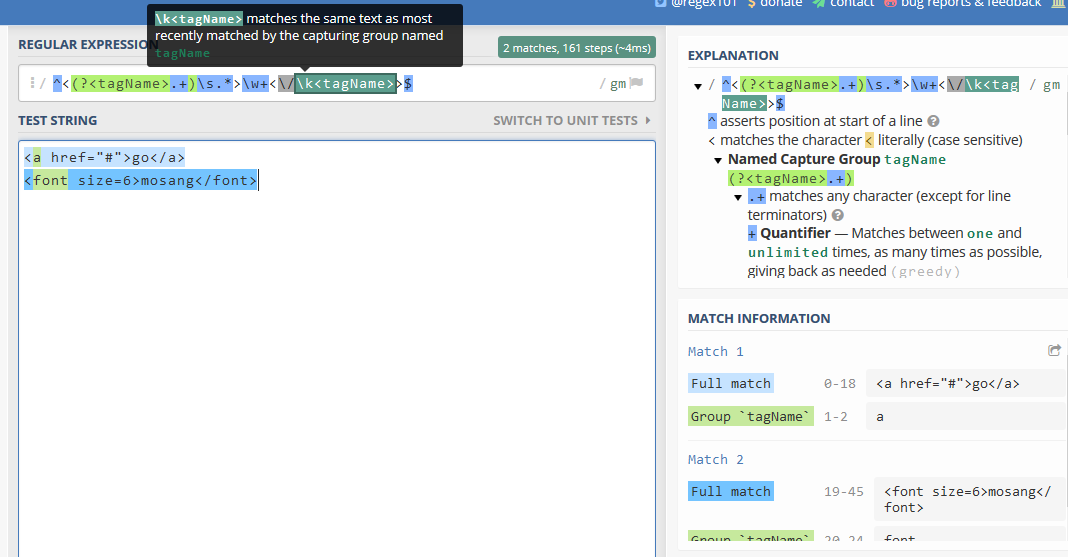
需要注意的是,命名分组不是正则的通用规则,不同语言支持组命名的书写格式有很大区别:

图片来源《正则指引》一书(作者:余晟)
2. 取消默认分组存储
在默认情况下,只要用()框定的内容,正则引擎就会自动分配组号,存储匹配分组,这样降低了引擎速度。如果我们不需要向后引用,可以通过(?:value)语法取消默认编组存储,其中“(”后面紧跟的“?:”会告诉引擎对于组(Value),不存储匹配的值以供后向引用。
如([0-9a-z]*)-(?:\d+),明确了第二个分组不进行编号存储,不提供向后引用。
字符集
字符集是由一对方括号“[]”括起来的字符集合。表示匹配[]包含的多个中的其中一个。
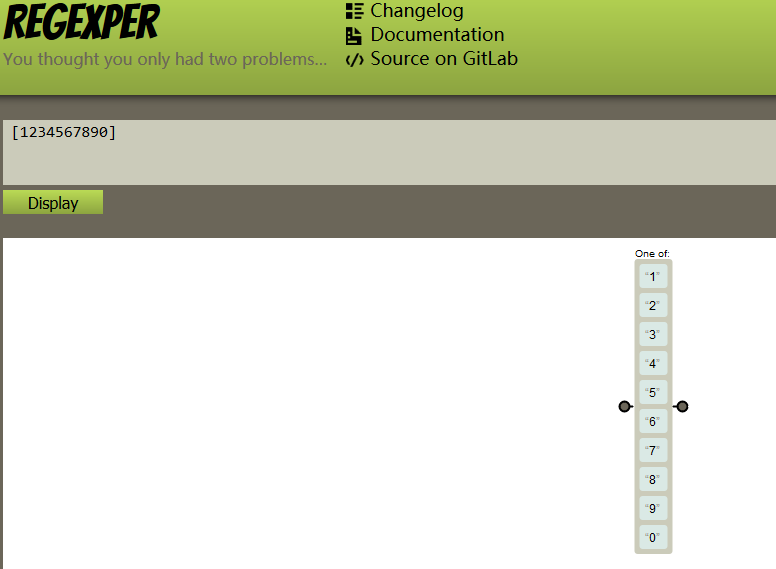
[1234567890]表示匹配0-9中任意一个字符,记住,是一个,在regexper中图示如下:
[ahsue]表示匹配a、h、s、u、e中任意一个字符,图示如下:

紧跟一个尖括号“^”(此时^不再是匹配位置的元字符),将会对字符集取反。结果是字符集将匹配任何不在方括号中的字符,如:[^ab]表示匹配不含a或b的字符串:
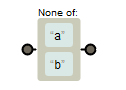
“–”在字符集中可代表范围,如[a-z]表示匹配a、b、c..x、y、z,26字母中的任意一个,[0-9]表示匹配0,1,2,3,4,5,6,7,8,9十个字符中任意一个,等效于[0123456789]。需要注意的是横线符号“-”在“[”开始的第一个字符时,它不再具有范围的特殊意义,而是一个普通字符,如[-23]匹配“-”,“2”,“3”三个字符中任意一个。
我们常用的一些特殊字符,就是字符集的简写,这也是我为什么不把这些特殊字符归为元字符的原因:
\d 代表 [0-9] \w 代表单词字符.这个是随正则表达式实现的不同而有些差异。绝大多数的正则表达式实现的单词字符集都包含了A-Za-z0-9_(单词定义为Unidcode的字母数字或下划线字符) \s 代表“空白字符”。这个也是和不同的实现有关的。在绝大多数的实现中,都包含了空格符和Tab符,以及回车换行符\r\n \S [^\s] \W [^\w] \D [^\d]
只有4个 字符具有特殊含义。它们是:“] \ ^ -”。“]”代表字符集定义的结束;“\”代表转义;“^”代表取反;“-”代表范围定义。不需要转义。例如,要搜索星号或加号+,你可以用”[+]”。当然,如果你对那些通常的元字符进行转义,你的正则表达式一样会工作得很好,但是这会降低可读性。
1. 12个元字符
学正则之前,你肯定翻过很多正则的书籍,被它们介绍的一大堆元字符搞得头大,如\d,\w,^,\A,$,\f……等等几十个,不仅难记而且容易混淆。实际上真正称得上元字符的只有12个,没错,对于元字符,你只需要记住这十二个:
[ ] \ ^ $ . | ? * + ( )
对于这12个元字符,如果你想在正则表达式中将这些字符用作文本字符,你需要用反斜杠“\”对其进行换码 (escape)也称为转义。
—— [] 表示一个字符集。
—— \ 有多重含义。一般情况下表示转义,或特殊字符的开始。如\d,这两个字符在一起,是一个整体,有特殊的含义,表示一个数字。如果与正整数连在一起用,表示向后引用,如\1表示引用第一个分组。
—— ^ 有多重含义。表达式开头位置表示输入字符串的开始位置,在字符集开始的位置中表示取反。
—— $ 表示输入字符串的结束位置。
—— | 逻辑“或”运算符,表示在多个条件中择其一。
—— ? 有多重含义。跟在表达式后,表示量词限定词0次或1次,如\d?;跟在量词限定词后,表示非贪婪模式,如\w{3,5}?;跟在括号开始位置表示特殊指令,如(?=pattern)、(?!pattern)、(?:pattern)、(?<!pattern)等表示零宽度断言,而(?m)放在在整个正则表达式前面,表示采用“多行模式”。
—— * 量词限定词,表示前面的子表达式可出现任意次。
—— + 量词限定词,表示前面的子表达式至少出现一次。
—— ( ) 有多重含义。一般表示表达式分组,与?连用有特殊指令,如(?=pattern)、(?:pattern)
2. 特殊字符
除了12个元字符外,其它有特殊含义字符我称之为特殊字符或简易字符。特殊字符是由转义字符与普通字符结合,形成有特殊含义的一类标识符,如:
|
\d
|
匹配一个数字字符。等价于[0-9]。
|
|
\D
|
匹配一个非数字字符。等价于[^0-9]。
|
|
\f
|
匹配一个换页符。等价于\x0c和\cL。
|
|
\n
|
匹配一个换行符。等价于\x0a和\cJ。
|
|
\r
|
匹配一个回车符。等价于\x0d和\cM。
|
|
\s
|
匹配任何不可见字符,包括空格、制表符、换页符等等。等价于[ \f\n\r\t\v]。
|
|
\S
|
匹配任何可见字符。等价于[^ \f\n\r\t\v]。
|
|
\t
|
匹配一个制表符。等价于\x09和\cI。
|
|
\v
|
匹配一个垂直制表符。等价于\x0b和\cK。
|
|
\w
|
匹配包括下划线的任何单词字符。类似但不等价于“[A-Za-z0-9_]”,这里的”单词”字符使用Unicode字符集。
|
|
\W
|
匹配任何非单词字符。等价于“[^A-Za-z0-9_]”。
|
|
\xn
|
匹配n,其中n为十六进制转义值。十六进制转义值必须为确定的两个数字长。例如,“\x41”匹配“A”。“\x041”则等价于“\x04&1”。正则表达式中可以使用ASCII编码。
|
|
\num
|
匹配num,其中num是一个正整数。对所获取的匹配的引用。例如,“(.)\1”匹配两个连续的相同字符。
|
|
\n
|
标识一个八进制转义值或一个向后引用。如果\n之前至少n个获取的子表达式,则n为向后引用。否则,如果n为八进制数字(0-7),则n为一个八进制转义值。
|
|
\nm
|
标识一个八进制转义值或一个向后引用。如果\nm之前至少有nm个获得子表达式,则nm为向后引用。如果\nm之前至少有n个获取,则n为一个后跟文字m的向后引用。如果前面的条件都不满足,若n和m均为八进制数字(0-7),则\nm将匹配八进制转义值nm。
|
|
\nml
|
如果n为八进制数字(0-7),且m和l均为八进制数字(0-7),则匹配八进制转义值nml。
|
|
\un
|
匹配n,其中n是一个用四个十六进制数字表示的Unicode字符。例如,\u00A9匹配版权符号(©)。
|
特殊字符代表的含义在w3school等网站都可以查到,这里就不做过多介绍。
1. 关于“匹配”一词的理解。
这是正则表达式用的最多的词,但是这个词对于初学者常常给人忽远忽近的感觉,有时候感觉理解了,有时候又觉得被绕进去了,离真正理解还很远。
我们在windows电脑上搜索文件,比如要搜所有MP4格式的视频,可以在搜索栏中输入“*.MP4”,搜索出来的文件就是mp4视频文件,假设搜索结果如下:
精通java.mp4 战狼2.MP4 三国央视版.MP4
用正则词汇来说,“*.MP4”匹配“精通java.mp4”、“战狼2.MP4”、“三国央视版.MP4”等字符串。
用我们通俗的话来说,“*”字符能代表“精通java”、“战狼2”、“三国央视版”等字符串,匹配就是这个正则表达式能代表这个字符串。
匹配结果,就是按照正则表达式的规则,在字符串中能不能找到符合此规则的字符串,能找到多少个字符串。如果不能找到称为不匹配,如果能找到一个或者多个,则每一个都称为一个匹配。
匹配这个词之所以常常令人费解,那是因为很多书把这个词义经常混淆一起用,把初学者搞晕了。
匹配有三种形式的存在:
——形容词性质的匹配:一个字符串“契合”一个正则,用于判断输出true或false。
——动词性质的匹配:在字符串中搜索符合正则的字符串。
——名词性质的匹配:字符串中满足正则的一部分,每一个部分都称为一个匹配。
这几个混在一起,很容易把人搞懵了。其实你只需要记住,匹配就是根据正则表达式这个“规则”,能在字符串中找到子字符串,就是匹配,就是这么简单。
2. 关于字符串的理解
正则表达式是判断、搜索字符串的专门语言,处理的一切对象都是字符串(文本也是字符串的一种,只不过包含换行等特殊符号而已),没有其他数据类型之分。
比如,对“18790”,我们在其它语言如C、Java、PHP中会认为这是一个数字,是一个整体,但是在正则中,它只是由5个数字组成的字符串,对,只是字符串而已,和“abcde”性质是一样的,并非一整数。
在正式进入正则学习之前,先安利几个好用的校验和测试工具:
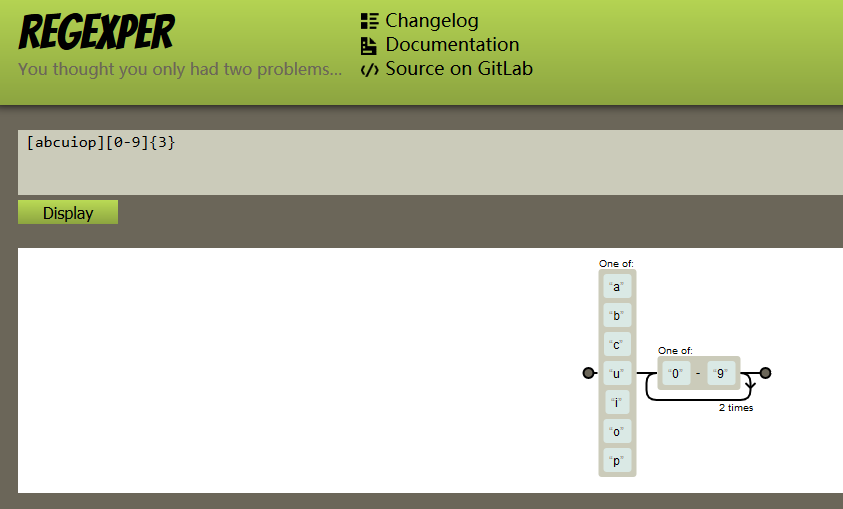
1. 在线正则结构分析工具 regexper。
regexper以直观的图例展现正则的结构,对分析和编写正则非常有帮助。
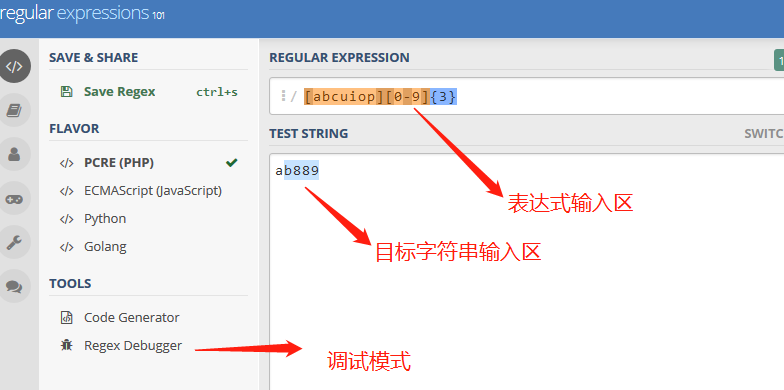
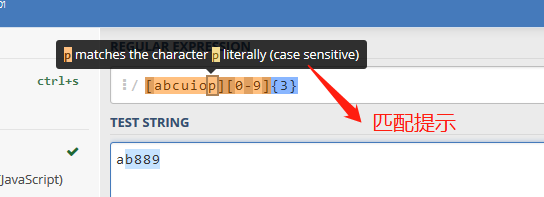
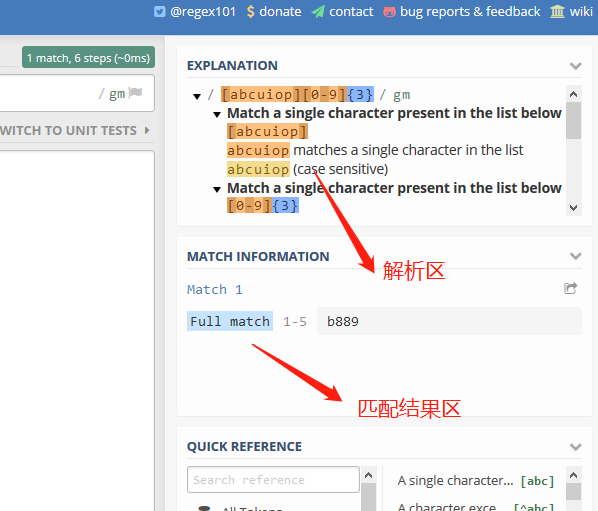
2. 正则在线测试工具regex101
regex101使用无需注册,打开即用。它不仅能快速响应匹配结果,设定各种匹配模式,还具有动态展现匹配过程功能的调试模式,对匹配过程以动画形式展现,是一款很赞的正则引擎。

3. 本地正则测试工具RegexBuddy
这是一个比较经典的正则工具,官网地址:http://www.regexbuddy.com/
RegexBuddy是个收费软件,不过网上有很多和谐版的下载,各位自行找度娘要吧。