成熟的人不问过去
聪明的人不问现在
豁达的人不问未来
这是我今天听到的一句话,觉得有些道理。
一个人要拿得起,也要放得下,要勇于承担责任,也要懂得舍弃没有意义的事和不值得珍惜的人。
一个聪明的人,常常懂得判断方向,一个优秀的人,总是善于学习,一个有生活阅历的人,往往看淡冷暖。
我们要做什么样的人,就会有什么样的人生态度。
原文作者:面条胡 来源http://www.zcool.com.cn/article/ZNDM2ODcy.html
1.行与列
表格的组成,就是行与列的组合,行与列的变化,赋予了表格多样性的特点。
行与列构成了单元格的长与高,不同的长高会有疏密之分,充实与透气之感。
根据目的及信息主体的不同,可通过行与列的显隐变化,来更好的满足信息的传达。
隐藏了纵向的线,更加强调行的特性,使横向信息更加连续通畅,则不强调纵向上下信息之间的对比;

ab2c57ecf723a84a0d304fd2e7f5.jpg
显现纵向的线,使上下行之间的信息增加了对比性。
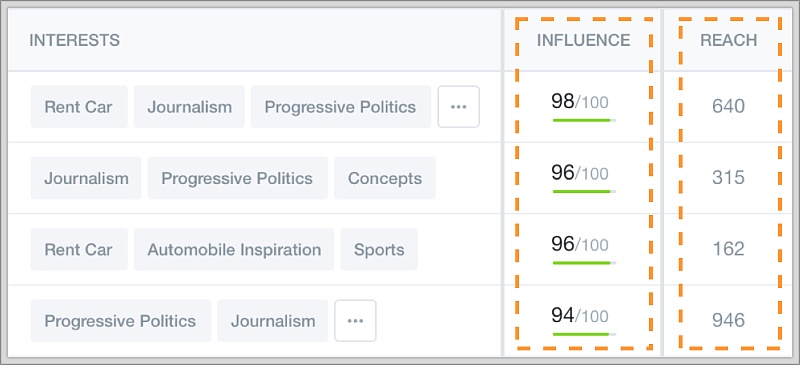
a34857ecf731a84a0e282b262791.jpg
2.对齐,高效的信息获取方式
表格内的信息通过对齐,会更加规范易理解,给用户视觉上的统一感,且视线流动顺畅,能够让人快速的捕捉到所要的内容。
文本信息左对齐,因为现代人的阅读方式习惯从左到右,符合正常的心智;
数据信息右对齐,更加方便数字大小的直观对比;
固定内容居中对齐,更好的信息呈现及表格空间的节省;
表头与信息内容对齐方式一致,一致性以达到简化,降低视觉噪音。
ef1757ecf774a84a0e282bfb7e89.jpg
3.减少视觉噪音,有效传达为本
信息内容的有效传达是表格的服务本质,就表格本身而言应该是隐型的,减少用户注意力,在保证整体结构的基础上,尽量减少或削弱所谓的视觉装饰。
07e057ecf794a84a0d304fb655cd.jpg
4.精简表头
表头在能够概括的情况下,尽量简炼、准确,一般可根据上下文关系来进行减短简化,以达到节省表格头部空间和减轻视觉压力的作用。
354d57ecfbafa84a0d304f34e090.jpg
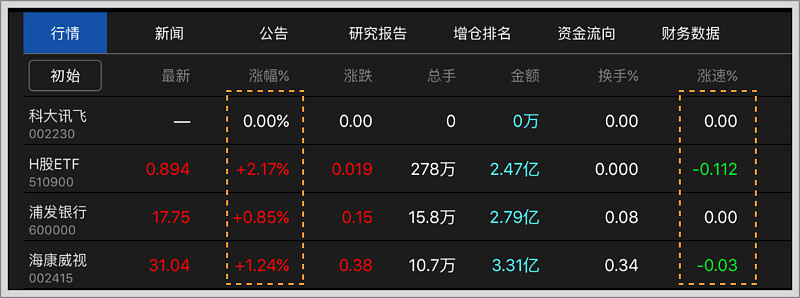
5.减少计算,为用户多想一步
根据当前数据,并在历史数据的基础上给出差值、总计等处理性的结果,可以直达用户所需即获取信息的目标,从而减少用户心算或者线下处理的麻烦。一般在数据对比中较常用到,通过当前数据和历史数据进行比较,来获得更多的直观信息,例如股票的数据变化、音乐排行榜排名变化等。
46d357ecf7e2a84a0d304f4325bf.jpg
6.空白数据,由“-”填充
表格中经常会出现空数据或无数据的情况,留白处理会给用户造成一定的困惑和误解,是系统没有加载出来吗?明智的做法,是用“-”来填充显示。

692857ecf7fda84a0d304ff2385c.jpg
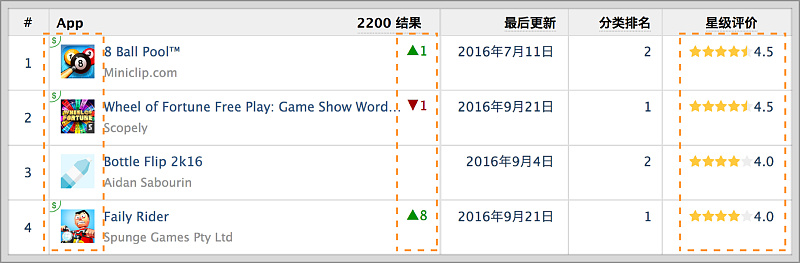
7.视觉层级
可通过背景、放大、颜色等处理,icon图标的应用,可使重要信息突出,不同功能模块区分(例如:表头与信息内容)、活跃表格氛围,增加视觉层次感等效果。
47f257ecf81aa84a0d304f34d8cb.jpg
表格的操作交互
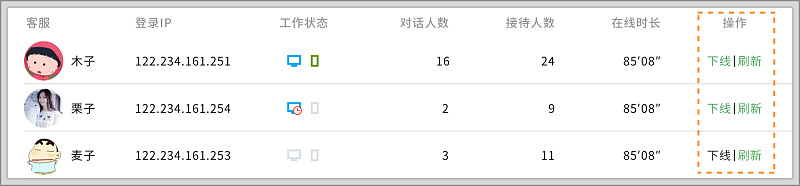
1.操作
对表格操作大体可分为显性操作和隐形操作。显性操作,指操作选项显示在行内,直观明显;
3f4557ecf852a84a0e282b507992.jpg
隐形操作,当鼠标悬停时或勾选才显示操作选项,使界面简洁明快,可减轻空间压力,减少干扰。

1ad657ecf897a84a0e282b80e3c7.jpg

dc0157ecf878a84a0d304f6f3795.jpg
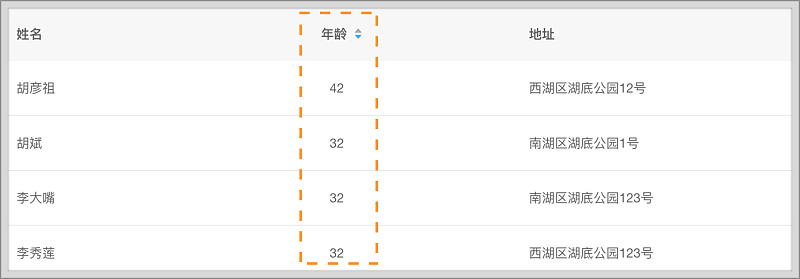
2.排序,让信息有序起来
可以让无序信息内容进行有序排列,排序分为升序和降序,一般用在数据、时间、数量上。
36ac57ecf8b1a84a0e282b4a2fd9.jpg
3.搜索和筛选,查找更方便
在大量的表格信息中,一一查找犹如大海捞针,但通过关键字搜索和条件筛选能够帮助用户快速的找到所需要的信息内容。

b98c57ecf8cca84a0d304f4575e8.jpg
4.固定表头,一目了然
当阅读丰富且繁多的表格时,由于屏幕有限,用户不得不拖动横向或纵向滚动条来阅读信息,固定表头,能过让用户明白当前单元格内信息的属性而不至于不知道该信息的意思,固定表头,也是一种界面友好性的体现。

9f6157ecf8e2a84a0d304f99dcdd.jpg
5.分页固定
若表格是分页处理的,分页会放在上部、下部或上下部均有,分页固定省去了用户需要翻到顶部或底部进行操作的麻烦。

ed5257ecf8fba84a0e282b483fa3.jpg
6.全选操作,效率加倍
若表格是分页,在某些情况下全选则需要考虑分为单页全选和整表全选,瀑布流式的加载则就不需要做区分了。

a1ca57ecf916a84a0e282b2f36e3.jpg
7.操作即反馈
当鼠标指针悬停在表格列或行时,给予变化提示,特别在信息列数较多的情况下更为重要,能够让人捕捉到所在的位置,而不至于视觉上的错行,能够降低人的心里压力和增加掌控感。

0f8657ecf935a84a0e282b0bcc72.jpg
8.根据所需提供相应的自定义和设置
服务于企业应用的数据表格,本身信息项目繁多,且需要满足不同行业不同角色的需求,默认表格一般会提供通用的字段指标,然后用户可根据自身所需添加或调整系统所提供的其它字段指标或进行自定义操作,让表格具有了弹性化的特征,以满足个性需求。
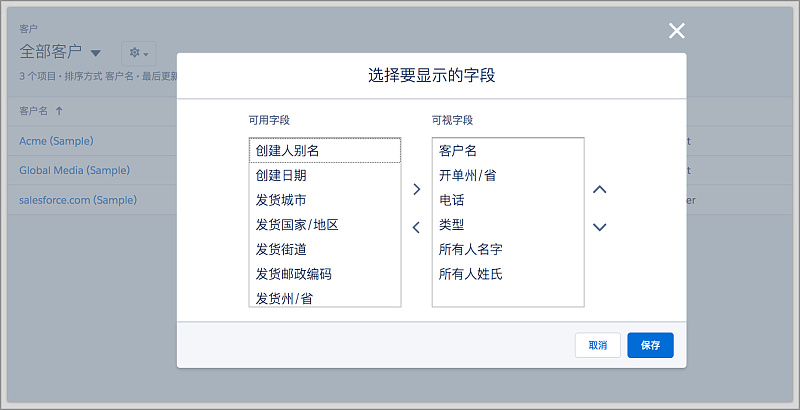
338457ecf949a84a0e282b015b90.jpg
总结
任何优秀的表格,本质上都是以用户所需的角度去设计服务,并有效的传达信息内容。

曾经一段时间,心里无比的痛苦,常常在半夜里梦中醒来,以前曾经想过做很多事,梦醒后发现现实的残酷,渐渐发现,自己习惯于在一种庸碌的生活中继续着毫无意义的努力,梦想离我越来越远了。
我终于与这段时间说了再见。
在这将近一年的时间里,做了很多自己喜欢做的事,学了很多东西,尝试并坚持去改变很多,终于感觉到生活重新变得有意义。
我们年轻的时候,最大的资本就是有很多可以尝试的机会,如果我们总是沉侵在畏首畏尾的犹豫中,乐于一种庸碌的工作,到头来将会一无所有。
我们常常不会为了曾经尝试努力去过做什么事而后悔,却常常会为未曾敢于去尝试追求自己的梦想而后悔。
经常面试一些应届大学毕业生和工作一两年的新人,看到他们的种种表现,就常常会想起自己毕业后出来工作的这几年,有些心酸。因为缺乏经验,很多观念我们都没有很好建立起来,有过迷茫,有过失落,有过难以言表的苦,这或许是一个必经的成长代价,但是有些道理我们尽早明白的话,或许对自己的发展更有帮助,我想对这个话题说几句。
1. 明白你的价值所在。任何一个公司,招聘一个员工都是只为了两件事:带来收益或节约成本。如果你不能带来这两个中的任何一种,那你就没有存在的价值,绝对就会被弃掉的。一个公司,本质上就是一群人聚在一起想着怎么挣钱,只不过是挣到的钱分配到各个人手中不同而已,公司是很现实的,绝对是利益的聚合体。一个人,要想在这个利益群体里立足,必须想清楚自己能给这个利益体带来什么独有的价值:要么创造收益,要么能压缩成本,有了这个目标,你的职业生涯一定会有所不同的。而很多新人,却常常不知道如何定位自己,所以改变命运的主动权始终掌握在别人的手中。
2.不要做一个善于加班不善于表达的人。很多人离开一个公司常常会抱怨甚至仇恨:为了这个公司很努力地工作,做了很多事,最终离开时却是两手空空。有些时候,沟通表达比埋头苦干更重要。很多事,需要的是大家的共同努力,单打独斗的力量是有限的,没有清楚的沟通,就没有很好的把共同的目标落实到具体配合上来。再一个,对自己的贡献,不要埋在自己的心里,也不要常常以为自己做了很多事就会得到别人的认同和肯定,善于向你的上司提出来,并且和他共同探讨更好的解决方案和思路,这样带来的结果就是让他知道你的工作,都是经过仔细斟酌和用心去做的。如果你是一个团队带队人,同时也要明白一个道理,常常加班,是一种制度的缺失,是一种沟通不足的结果,是要求别人的额外付出,是降低生活品质的做法,必然会被要求额外回报,如果长期没有得到超额的回报,矛盾就会逐渐积累起来,直到有一天不可收拾地爆发,当然,如果自己是老板就另当别论。
3.你所有的尊重都是自己努力赢得的。一个做事漏洞百出的人,一个工作心不在焉的人,一个得过且过的人,一个常常言行不一的人…任何人不会发至内心对他尊重的。一个人,获得尊重常常来自对自己不断要求,尊重不是别人给的,更不是祈求获取的。做事专业、付出更多、更有服务意识、更有团队精神、更善于寻找方法工具、更能为大家带来收益和利益…能让你变得出众,赢得尊重。
4.更多关注别人的长处,善于从周围的人身上学到优点。很多人,常常抱怨身边的某某同事的不好,看不惯公司的种种做法,结果把自己弄得越来越不想在这个地方待下去,而真正从这个公司出来后却发现这段时间好像没有真正收获到什么。其实,我们常常忘了自己的目标,在一个阶段中,在一个公司里,自己真正需要得到的是什么,常常把精力错误地放到那些枝节上。我观察身边很多成功的人,无一例外,都是目标性很强的人,会把目光放在吸收别人优点上,得到不断的自我成长,他们从不会把时间和精力放在那些枝节之上。
5. 善于改良而不是改造。一个新人常常犯一个毛病,就是到一个新的环境,似乎对什么都看不惯,什么都不顺眼,恨不得大刀阔斧来个翻天覆地的改造,而这样的结果常常是,由于前人的工作遭到的否定,受到很大的阻力,结果往往是差强人意甚至失败。更正确的做法是,先适应,并且不要承诺太高,探清各种问题的根源,然后从一个点突破,做一些成绩出来,在慢慢把改革全面推开。
6.不断锻炼自己对高端指令的解码能力。上司说的话常常是非常简单的,他们真正需要得到的结果常常藏在简单话中,我们要善于将这些简单的指令解码成能实际操作的工作计划。这里说的高端指令解读能力,不是说对职位高的人的话语解读,而是说能从很简单的信息中扩展开来,寻找到核心需求,再从核心需求中发散细化其他需求的一种能力。
7.选择一个公司,公司的大小与你的收益没有太大关系。很多人都有一种错觉,就是到大公司会得到更高报酬,更多收益,实际上这是一种误区。一个公司规模再大再有钱,也不会无故多给你高出一分的报酬,只会根据你为公司创造的收益决定你的报酬。任何时候一定要明白自己真正需要的是什么,如果你想多学习一些成熟的管理模式,规则规范,那就去比较大型的公司,如果你需要锻炼自己独立性,提高自己的业务开发能力到小公司或许更合适。
8.去掉弱者心态。有弱者心态的人,处处怕被受到伤害,很难有主动把握自己命运的观念,不会如何与人处事,常常表现出情绪化的行为,这样的心态是很难成就大事的。
9. 方向比位置更重要。选择一个职位、一个公司,一定要符合自己的目标发展,职位是要放在方向之后考虑的。一个没有自己坚定目标的人,常常成为公司的橡皮贴,哪里缺人、哪里临时有需要,就会把你派去,根本不会考虑是否符合你的个人发展。因为都是做一些琐碎的事,不会做出什么大不了的成绩,久了就会丧失自己的优势,而公司反而觉得你也没有做出什么不得了的业绩,努力得不到应有的认可,个人悲剧往往就是这样造成的。还有,如果你的上司是一个权力欲强、喜欢事无巨细都要自己严格控制,常常把目光放在凌锁的事情上,整个部门或者公司没有明确的方向性,天天忙得不可开交却都是在做垃圾回收式的工作,还是趁早离开吧。如果你是一个主管,就应该把精力放在发展方向的策划思考上,为下属创造施展才能的条件,让他们去做具体的事,那些枝枝节节的事情如果对目标影响不大,就不要计较,不要让你的下属和你一起做事感到没有前途,感到迷茫和绝望。
10. 不要让所谓的企业文化迷失了自己。“企业文化”都是利益掌控者获得更多利益的思想工具,那些所谓的理论对你个人并没有多大的帮助。我这句话并不是说要让你不认同企业文化这个东西,如果你想个人有发展,一定要把这个事分析透彻。一个人要想获得发展、得到更多收获,绝不是“企业文化”能带给你的,把时间多用在学会怎么与人愉悦相处,怎么提升自己的知识结构、怎么锻炼自己的情商、怎么分析需求、怎么了解市场、怎么提升自己的技术能力、业务水平上,会对你有帮助的。当然,当你想有一天自己做老板的时候,再深入研究一下企业文化吧。
我的一些浅见,以自己的小小经验,希望对那些迷茫的新人们有一个小小的启发。
heiry wu
交叉补贴原理:当你免费或者低价获得一件产品或服务的同时,为另一件产品或服务付费,实际上用户的总支出是大于总收益的,也就是其实用户自以为占到了便宜实际上却未必如此,对商家而言,表面上是做赔本赚吆喝的,实际上却从另外渠道获得了巨大收益以弥补那部分低价出售的产品或者服务,因此商家总收益是不低于总付出的。
这一原理在生活中得到了普遍的运用。旅行社就是个运用交叉补贴的高手,对这一原理喜爱有加,乐此不疲,他们往往打出超低价的报团费招牌,团费甚至低于单程机票的钱,以吸引游客参团,然而实际旅行中,游客显然已经被导游无形绑架了,导游利用直接或者间接强迫购物的方式获取暴利,以此来补贴亏损的报团费。前不久闹的沸沸扬扬的香港导游阿珍骂人事件、前国乒手陈佑铭因被强迫购物气死事件等都是旅行社用交叉补贴营销换来的恶果。有些餐厅或者美容厅往往派送诱人的优惠券,吸引人前去消费,但消费者在实际消费中却往往要付出比正常更高昂的代价。商家赠送手机,捆绑资费套餐,免费送饮水机,源源不断地从桶装水中获得更多的利润,这些都是最常见的运用。
这一原理在互联网中的体现最初是从游戏开始的,当时游戏厂商引发了大量的游戏点卡,低价或者免费派送,吸引大量用户前去消费,然而在游戏中却设置了种种门槛,诱使或者迫使玩家更多付费。但这个游戏运营模式在激烈竞争下已经被互联网淘汰,现在却以其他方式存在。当前的网络游戏,绝大多数都是免费的,商家以道具、虚拟货币等其他手段来获益,其实这本质上也还是交叉补贴,只不过是换了种表现方式罢了。
更高级的交叉补贴模式在互联网中得到了广泛运用,也是现在最主流的互联网商业模式。商家不再以旅行社式涸泽而渔的赤裸裸地运用交叉补贴,直接向消费者收费,而是通过免费向普通网民提供服务,向商家或者企业收费的模式获得补贴收益,直接消费者不再支付补贴部分而是由另外的第三方来买单。例如网络招聘,普通网民是免费注册获取招聘信息的,而在网站登记招聘信息的企业是需要付费的。360杀毒软件,对普通用户是全免费的,而对企业用的服务器版却是收费的,网络游戏是免费的而收益更多来自道具买卖和广告嵌入,而腾讯QQ则将这一原理用到了极致。这种交叉补贴方式在互联网上得到了最广泛的运用,也是最主流的互联网商业模式,它舍弃了最原始的交叉补贴原理运用形式,而是将受益对象和补贴对象分离。
交叉补贴通过低价格或者免费迅速获取大量用户,占领市场份额,拥有大规模的用户终端,而通过衍生品或者增值服务获取收益。但是这一原理运用的前提是边际用户成本较低,也就是增加一个用户增加的成本非常低,否则商家将难以承受带来的巨大成本。满足这一条件的最好运用莫过于互联网了,因为互联网的运用成本相对较低,多数互联网应用产品边际成本微乎其微,这使得交叉补贴在互联网中得到了最好发挥。
以前拍的,寒冬里,窗外下着大雪,我在屋子里看书、听音乐,一种很安静、惬意的感觉。

窗外的大雪

窗外的大雪

窗外的大雪
require_once(“alipay_service.php”);
require_once(“alipay_config.php”);
$array=explode(“@”,$info[“spc”]);
$arraynum=explode(“@”,$info[“slc”]);
$arrayinfo=array(); //创建数组$arrayinfo_count=array(); //创建数组for($i=0;$iif($array[$i]!=””){$m=$i+1;$sqlcart=mysql_query(“select * from tb_commodity where tb_commodity_id='”.$array[$i].”‘”,$conn);$infocart=mysql_fetch_array($sqlcart);//读取数据库中数据
array_push($arrayinfo,$infocart[tb_commodity_name]);//将购物商品的名称写入到数组中
array_push($arrayinfo_count,”商品 $m :$infocart[tb_commodity_name] 数量:$arraynum[$i]”); //将购物商品的数量写入到数组中}}
$commodity_name=implode(‘,’,$arrayinfo); //获取商品名称
$commodity_count=implode(‘,’,$arrayinfo_count); //获取商品描述信息
$parameter = array(“service” => “trade_create_by_buyer”, //交易类型,必填实物交易=trade_create_by_buyer(需要填写物流)”partner” =>$partner, //合作商户号
“return_url” =>$return_url, //同步返回”
notify_url” =>$notify_url, //异步返回
“_input_charset” => $_input_charset, //字符集,默认为GBK
“subject” => $commodity_name, //商品名称,必填
“body” => $commodity_count, //商品描述,必填
“out_trade_no” => $ddnumber,//商品外部交易号,订单号,必填,每次测试都须修改
“logistics_fee”=>$yprice, //物流配送费用
“logistics_payment”=>’BUYER_PAY’, //物流配送费用付款方式:BUYER_PAY(买家支付)
“logistics_type”=>’EXPRESS’,// 物流配送方式:POST(平邮)、EMS(EMS)、EXPRESS(其他快递)
“price” => $amount,//商品单价,必填
“payment_type”=>”1”, // 默认为1,不需要修改
“quantity” => “1”, //商品数量,必填
“show_url” => $show_url,//商品相关网站
“seller_email” => $seller_email//卖家邮箱,必填);
$alipay = new alipay_service($parameter,$security_code,$sign_type);$link=$alipay->create_url();$smarty->assign(“link”,$link);

