无论个人还是组织,在追求改变、进步和提升的过程中,要想取得实质性和长期的成功,大都需要从小到大、从慢到快、从局部到整体逐步地改变,也就是一点一滴、循序渐进的方式推进,从而最终达成目标。这叫做“进化论原则”,这是一个生物学规律,也是一个社会学定律。
其本质思想,是无论生物体生理,还是人的心理、社会文化、群体行为,都是具有惯性的,而要改变这种惯性,需要持续长时间的微小变化积累。正如矫正牙齿、骨骼的方式,需要长时间持续给予微小的力量来改变,若强力扭转,只会折断折损,而达不到矫正的目的。
一个人要想减脂成功,不是一下子严控饮食,突增运动量,突击能够达成;而是,每天形成一定的热量缺口,慢慢递进式的增加,到了一定程度,再调整方案,使得身体适应节奏,不会报复性反弹,从而稳步到达目的。
改变一个拖延的习惯,是通过把事情拆解为一般事务性和深度事务,从一般性事务的立即行动,自然过渡到需要深度思考的缓步行动,曾风靡全球的畅销书《原子习惯》说的即是这个道理。
一项社会改革能实现,必定是一个一个具体问题的解决,制度柔性的过渡,慢慢达成的;所有激进的方式,只会带来动荡、割裂和反弹。台湾土地改革,是世界公认的学习典范,与大陆共党残暴血腥的方式不同,国民政府在台湾的土地改革——“三七五减租”、“公地放领”、“耕者有其田”循序漸進的三部曲,是温和渐进式的改良,照顾到了各方利益,整个过程没有杀人流血,成功实现了和谐与蓬勃发展的良性结果,成为世界土地政策的学习榜样。已经灭亡和可预见必将灭亡共产主义国家,以及南美阿根廷、委内瑞拉等国的统治者,都企图以简单粗暴共产乌托邦思维改造社会,最后都是血流成河、贫困、饥荒与仇恨遍地的结局。
就在五十年前,新竹一帶的佃租率仍高達七○%,也就是說,農民一年的辛勤收穫,有七成要繳給地主。台北、台中、台南等七縣市,佃租率平均也高達五七%。
直到陳誠來到台灣。
一九四八年,國共內戰正在生死關頭,陳誠被任命為台灣省主席。
懷著「民有、民治、民享」社會公平的夢想,看見當時貧富差距如此懸殊的台灣農村,陳誠決意重新分配土地所有權。
但陳誠的改革,不同於其他第三世界國家,雖然也引起一些大地主不滿,但始終沒有造成血淚抗爭。最主要的原因是,他以循序漸進的三部曲:三七五減租、公地放領、耕者有其田,來完成改革大計,每一步都是溫和理性的財富重分配。
這些改革使台灣農業生產力大增,糧食比前一年增產三成,佃農收益比前一年增加四三%。不僅農村貧富差距縮小,台灣也自此有了邁向工業化的厚實基礎。—— 《土地改革第一波 陳誠》《天下雜誌》2012-06-25
年轻时,没明白这个道理,后来读了很多历史巨人的思想,结合实际的经验,方悟出其中的真谛。
因復語張曰:「爾性太急切,且易衝動。爾當知世上有許多事,皆非躁急之舉動可以成功者,唯步驟一致漸進之行動,乃可得真正之進步;換言之,即全國人民程度進至適當之水平線後,仍將感效果之遲緩。然余之經驗告余,躁急者百分之力量,祇能得一分之收穫;而徒求快意一時之舉動,決不能致中國於富強,惟堅忍卓絕之苦幹,始能得理想中之成功。」 張聞言,頗感動,誠摯言日:「夫人,余已覺悟此舉…
——《西安事變回憶錄 》 宋美齡著 中華民國二十六年一月 中正文教基金會
…社會是種種勢力造成的,改造社會須要改造社會的種種勢力。這種改造一定是零碎的改造,——一點一滴的改造,一尺一步的改造。無論你的志願如何宏大,理想如何徹底,計劃如何偉大,你總不能攏統的改造,你總不能不做這種「得寸進寸,得尺進尺」的工夫。所以我說:社會的改造是這種制度那種制度的改造,是這種思想那種思想的改造,是這個家庭那個家庭的改造,是這個學堂那個學堂的改造。
—— 《非個人主義的新生活》胡適 1920年1月15日上海《時事新報》
——《原鄉精神:台灣的典範故事》 馬英九著 天下遠見出版公司 2007年
项目中使用Firebase JWT库做Token验证,确实很好用,减少了很多繁琐的判断,不过要使用它自带的验证方法,命名就必须符合它的标准。
如,起始时间,过期时间等都需要按照它的标准命名:
$tokenData = [ 'iat' => $issuedAt, //Token核发时间,标准写法,名称固定为 iat 'exp' => $expirationTime, //Token过期时间 ,标准写法,名称固定为 exp ];
验证非常方便,只需要调用相应的异常结果就可以了,不必自己拆解出来做复杂的判断。
try {
$decoded = JWT::decode($token, new Key($this->secretKey, 'HS256'));
$decodeToken = (array)$decoded;
} catch (ExpiredException $e) {//过期异常
$message = 'Token has expired';
$outData = ['code' => 401, 'message' => $message];
return json($outData);
} catch (SignatureInvalidException $e) { //签名不正确,被篡改
$message = 'Invalid token signature';
$outData = ['code' => 401, 'message' => $message];
return json($outData);
} catch (Exception $e) { //格式不符或者被篡改
$message = 'Token validation failed';
$message = 'Verify Fail: permission denied';
$outData = ['code' => 401, 'message' => $message];
return json($outData);
}
最近项目中使用Fabric.js做图像动态标记,被有些小问题缠住,花了很多时间去琢磨,有些甚至弄了一两天才理明白,特此记录。
1.canvas的width、height与style.width、style.height须一致,否则画出图形会变形或只显示图像的一部分。
canvasRef.value.width = img.naturalWidth; canvasRef.value.height = img.naturalHeight; canvasRef.value.style.width = img.naturalWidth + 'px'; canvasRef.value.style.height = img.naturalHeight + 'px';
看资料,fabric的画布实际上有三层(下图来自:jb51)
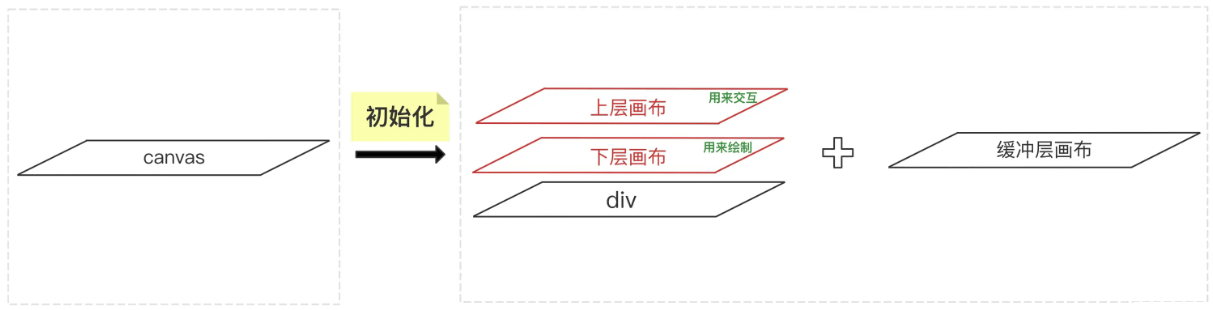
2.可以创建离屏/静态画布,不必在页面中显示,整体绘制完毕后再通过图像对象输出。
const canvas = new fabric.StaticCanvas(null, {
width: originWidth,
height: originHeight
});
离屏画布的节点引用设置为null,一样可以设置宽高。
3. 如果有背景图片,所有创建的元素都需要在创建背景图片的函数体内完成,不能在函数体外创建,否则导出的图片将背景不可见。就是这个问题,我困扰了两天,开始以为是跨域问题,背景图片格式的问题等等,后来发现原因在此。
nextTick(
() => {
canvasRef.value.width = img.naturalWidth;
canvasRef.value.height = img.naturalHeight;
canvasRef.value.style.width = img.naturalWidth + 'px';
canvasRef.value.style.height = img.naturalHeight + 'px';
let currentCanvas = new fabric.Canvas(canvasRef.value, {
selectionColor: '#4fb8d3',
selectionLineWidth: 0
});
fabric.Image.fromURL(imgUrl, (img) => { //必须将绘制的文本和图形放到这个背景图函数体内,否则无法显示背景图
currentCanvas.setBackgroundImage(
img,
currentCanvas.renderAll.bind(currentCanvas)
);
currentCanvas.backgroundImage.scaleToWidth(currentCanvas.width);
currentCanvas.backgroundImage.scaleToHeight(currentCanvas.height);
for (let key in LocationObj) {
let locationNum = LocationObj[key][0].bbox;
let arr = locationNum.split(',');
let numberArray = arr.map(Number);
let rect = new fabric.Rect({
left: numberArray[0],
top: numberArray[1],
width: numberArray[2] - numberArray[0],
height: numberArray[3] - numberArray[1],
fill: 'transparent',
stroke: 'rgb(235,64,64,0.9)',
strokeWidth: 3,
strokeDashArray: [5, 5]
});
let text = new fabric.Text(
' ' +
messageMap.value[key] +
' - ' +
Number(LocationObj[key][0].conf) * 100 +
'%' +
' ',
{
left: numberArray[0], // 文本的X坐标
top: numberArray[1] - 22,
fontSize: 22, // 字体大小
textBackgroundColor: '#eb4040', // 文字背景颜色
textBackgroundColor: 'rgb(235,64,64,0.8)',
hasControls: false, // 不显示控件
hasBorders: false, // 不显示边框
fontWeight: 'normal',
fill: 'white',
padding: 20,
lineHeight: 3,
textAlign: 'right',
fontFamily: 'Arial,Microsoft YaHei'
}
);
currentCanvas.add(rect);
currentCanvas.add(text);
currentCanvas.renderAll();
// rect.set('selectable', false);
// text.set('selectable', false);
}
downURL.value = currentCanvas.toDataURL({
format: 'png',
quality: 0.9
});
downLink.value.download = 'X_RayImg.png';
});
},
{ crossOrigin: 'Anonymous' }
);
学生时代,上了十几年的学,读过诸多所谓的“大师”、“伟人”的名篇名著,却从没有过真正的内心触动。一直很奇怪,为什么那些所谓的名篇巨著,总是让人觉得或是云里雾里,或是无病呻吟,或是不着边际,甚至故弄玄虚?既没有让人自然接纳的美感,也没有让人真正体会到那些宣扬的“智慧”,读多了这样的书,不但没有理清种种疑惑,反而愈发使人迷茫。直到N年前,误入《易卜生主义》,从此一发不可收拾,开启了真正启蒙的时刻。
说起来真是无比的悲哀,人生几乎过半,才恍然大悟,什么才是真正的智慧,什么才是一辈子最重要的东西。在最好的青春年华里,时间和精力都浪费在了洗脑教育上,这种教育往脑中灌入的都是垃圾,这些垃圾让人失去自我,备感迷茫。等到有所觉察,再往外一点点掏出垃圾时,人生已经过去了一半,却不得不又从零开始起步。
跟随着《易卜生主义》的线索,一点点看到了智者的光芒,一步步看到真正英雄的身影,慢慢看清那些篡改历史、丑化良善的跳梁小丑们的真面目。
当年张维迎在与林毅夫公开辩论产业政策时,有一段精彩的论述:
… 所以我们看到, 一旦政府鼓励任何一个产业, 这个产业一定会变得产能过剩, 危机四伏。 凡是政府扶持的产业, 不把它做砸绝不会罢手。
当然, 做砸了是不是罢手也不一定, 因为政府官员还可以错上加错。 创新的不可预见性意味着产业政策一定会出现错误: 支持了不该支持的企业和产业。但政府官员一般不愿承认自己的错误, 因为错误会暴露自己的无知; 掩盖错误的一个办法是对失败的项目提供更多的支持。 这就从无知走向无耻。
—— 《政府的边界》张维迎 林毅夫 著 民主与建设出版社2017-03-01 P21
管理学上也有一个普遍的认知:一个人能力越低,一旦偶然身居要职或高位,他就越热衷于证明自己的了不起,做出各种荒唐举措,为了掩盖荒唐举措造成的损失和后果,又会制造更多更加荒唐的措施。低能的管理者,往往不会把时间精力用于改进工作上,而是不断做表面文章,以彰显不凡来获得周围人对自己的认可。
小人得志时,最热衷于宣扬自己的“伟大”、”光荣“、”正确“,最常用的手段,就是不断编造谎言,用尽诋毁手段贬低人格高大的人,并用暴力打手严密阻止真实信息的传播。东施知道自己很丑,于是逢人就编造自己辉煌的过去,并极力渲染西施是多么的丑陋和不堪,严密控制村外的信息输入,极尽谎言与威胁,使得周围的人都慑于淫威而宣扬她是村里最美的人。但凡一个正常人出现,都会立马把她照回原型,于是她就编造各种“辱村”论,把其它被洗脑的工具人拉到拉到同一战线,鼓动对立。一旦西施真的出现,她就彻底无地自容,只会用更竭嘶底里、更荒谬幼稚的方式来对抗。
从《易卜生主义》到《演化论与存疑主义》《问题与主义》《新思潮的意义》《贞操问题》《科学与人生观》《不朽》《我们对西洋近代文明的态度》,再到《时论集》, 加上几十年的日记,给人的思维冲击已经不能简单用“巨大”来形容了。在大量阅读适之先生的著作后,猛然惊醒,韩寒当年是多么的清醒而睿智,不禁为自己花了那么多宝贵年华在垃圾教育上痛心不已。
![]()
当你有一天看到,站在面前的西施不仅美丽动人,且人格魅力十足时,你一定会认清那个拼命诋毁她、且想尽一切办法阻止你和其接触的东施。我终于明白了,为什么满世界都称“我的朋友胡适之”,获得过三十多所世界顶级名校荣誉博士学位的人,一生没有拥过一兵一卒,没加入任何党派,至死践行科学、民主与自由的学者,却被列为“战犯”,被工具人发起一波又一波的批判浪潮并写下几百万字批判“巨著”。![]()
快两年没更新,今天好想写点东西。
大学时的好同学,今天因为癌症走了,早上听闻这个消息,很难过,一天都感觉有点恍惚,没有心思做事。
大学时,几乎每天吃饭、上课都是在一起,同院的好几个同学甚至分不清我俩。有一次课间,两位同院的女生从身边走过,其中一个过来打招呼,对着我却叫的是他的名字,旁边女生顿时笑出声来。隔壁寝室的一个同学还说我们是双胞胎,长得很像,又经常在一起。
聪明,谦逊、厚道,是他最大的三个特点。
他天资聪颖,学什么都很快,记忆力极好。总成绩整个学院名列前茅,班里曾是第一、第二名,英语四六级都一次过,后来通过公考入职了国资委,随后又考研读了硕士。
他写得一手漂亮的字,自带行书风,错落有致,工整干净,非常有条理。
谦逊这种品质在他身上体现的尤为突出。我大概是整个大学期间和他走的最近,接触最多的人,但我从未见过他夸耀过什么,甚至隐式地炫耀过什么,从未有半点的傲气,对任何人都非常谦逊,做人行事都非常低调。
厚道,是无法伪装的。一个人是否厚道,长期的一言一行,绝对是可以感知的。他就是一个非常厚道的人,我们几年的相处,他给我的印象,是实在、真诚,没有多余的成分。
他在很多方面,潜移默化间影响了我。
管理的两种形态
世间有两种事,一种是私域的事,个体完全能做主的事,也叫私人之事;一种是公域的事,即众人的事,不属于任何个体,需要多数人同意的才能决定的事,也叫公共事务。这两种事决定了管理的不同形态。
私人之事,只要履行基本的道德和法律义务,就能完全自己做主,完全自己决策,完全自己承担结果。例如,生活中,自己的薪水怎么花,只要不用在违法消费上,别人就无权干涉,完全自己能做主。至于,花了之后产生的后果,也是完全自己承担。例如,花太多在吃的方面,长胖了;花太多在玩的方面,结果生活捉襟见肘;花在买各种奇装异服上,穿出去受到大家的诟病等,这些决策依照个人意志或喜好做出,后果也完全是自己承担。所以私人之事的管理,更多在于满足个人意志,不需要太在乎他人感受,更多在于能独立承担后果。
公共事务,不单属于任何个体,决策的也不应由某个或几个人决定,除非得到众人的授权,因为决策的后果是大家共同承受的,而非由决策的那些少数人来承受。因此公共事务的管理必须是公共意志的贯彻,也就是决策须经由多数人同意,执行的后果由所有人来承担。公共事务的管理核心在于说服,在于把分散的意志集中起来,从而共同实践,共同承担带来的后果。最典型的公共事务就是政治,现代文明政治的核心理念在于主权在民,即民有、民治、民享,国家是一种公共事务,是大家共同的事,管理权在全体人民,而不是少数权贵家族的特权,更不是所谓“枪杆子里出政权”的某些政党的专属。对于政治,国父孙中山先生在《三民主义》中给出最精辟的解释,他说:“政,就是众人的事,治就是管理,管理众人的事便是政治”。
今天開始來講民權主義。什麼叫做民權主義呢?現在要把民權來定一個解釋,便要先知道甚麼是民。大凡有團體有組織的眾人,就叫做民。什麼是權呢?權就是力量,就是威勢。有行使命令的力量,有制服群倫的力量,就叫做權。把民同權合攏起來說,民權就是人民的政治力量。甚麼是叫做政治的力量呢?我們要明白這個道理,便要先明白甚麼是政治。政治兩字的意思,淺而言之,政就是眾人的事,治就是管理,管理眾人的事便是政治。有管理眾人之事的力量,便是政權。今以人民管理政事,便叫做民權。—— 民國13年3月9日孫中山于國立廣東高等師範學校演講,《三民主義之民權第一講》
为了能落地有效执行公共意志,政治通常以选票方式来选择和罢黜一个政党来体现公共意志,用民意代表代议执行公共意志,用民意团体和自由媒体来监察公共意志执行的成效。出色的政治家,在于使自己的理念获得大家认同,具有强大的说服能力,使得大家同意按照他的理念来推进公共事务,共同承担这样带来的后果。所以,民主国家的总统竞选人,不管是否最终政绩卓越,但首先必须是个有明星般感染力的人,有强大说服力,使得大众一心,认同他的施政理念。
管理是一种社会性实践,是概率性决策,无人能预知决策的正确性。个人事务决策,本质上是对私产的处置,无论是在追求增值的过程还是变现的过程,抑或纯个人喜好和理想,收益和风险都由决策者承担;公共事物决策,本质上是对公产的处置,收益往往存在外部性,简而言之就是收益可能只有极少数人获得,风险或者说后果却由全体人来承受。所以,个人事务完全可以由个人自由意愿来决定,而公共事务的决策,切不可自认是先知先贤,不经过众人的首肯和选择,而进入救世主模式,而且民众被禁用了切换替代功能,最后全体人民就会承受灾难后果。无数历史事实早已证实,共产世界的红太阳们,极端宗教的“先知”们,“枪杆子”下极权专制的“伟大领袖”们,无一不是国家民族的巨大灾星,无数冤魂白骨成了他们“伟大思想”的实验结果。
企业管理,核心在于承担风险
我们通常所说的企业管理,对象当然是指追求经济收益的民营企业,也就是通常的有限责任公司和股份有限公司,非主流的低效国企并不在此讨论之列。
单股东或多股东的公司,或是上市的广泛分散的多股东公司,本质上都是一样,决策上是单一或多代理人执行的区分而已。 (更多…)



